今日:0
文章:81
今日:0
文章:29
今日:0
文章:57
今日:0
文章:100
今日:0
文章:12
今日:0
文章:19
今日:0
文章:0

9276

随着Windows 10的完善,目前win10系统下可以安装Linux子系统,通过安装子系统就不必再装双系统,但是子系统安装好后运行的窗口类似开启了一个终端,没有图形界面,那么,这个经验就是教大家怎么去安装Linux图形界面。安装方法就不在这里讲述了,这里我们假定大家已经装好Linux系统进入方法有以下几种:1。在左下角的Cortana中搜索Ubuntu,点击进入,看到的界面就如同我们在Ubuntu下的终端界面,在这个窗口测试一下ls命令,无误。2.通过CMD/Windows Power Shell中,输入bash进入也是可以的进入正题目前网络上主要为两种方案:一。远程桌面协议(参考:https://jingyan.baidu.com/article/ed2a5d1f98577809f6be17a3.html)我们在Linux命令行下依次输入以下命令:更新sudo apt-get update安装 xorgsudo apt-get install xorg安装xfce4sudo apt-get install xfce4安装xrdpsudo apt-get install xrdp配置xrdpsudo sed -i 's/port=3389/port=自定义为你自己的端口/g' /etc/xrdp/xrdp.ini上面是配置端口,其中第一个port3389为固定端口,后一个port为对外访问端口,也即是你之后连进来的端口向xsession中写入xfce4-sessionsudo echo xfce4-session >~/.xsession重启xrdp服务sudo service xrdp restart如果有防火墙,允许就好了。以上内容设置完成后,就可以通过远程桌面连接上去了,用户名与密码为你Linux子系统的密码二。使用第三方插件实现(例如:X-Windows 资料来源:https://blog.csdn.net/u011138447/article/details/78262369)
20266

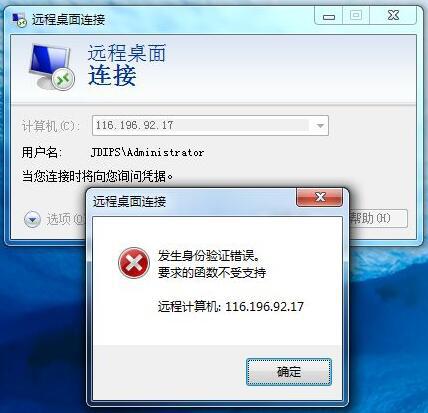
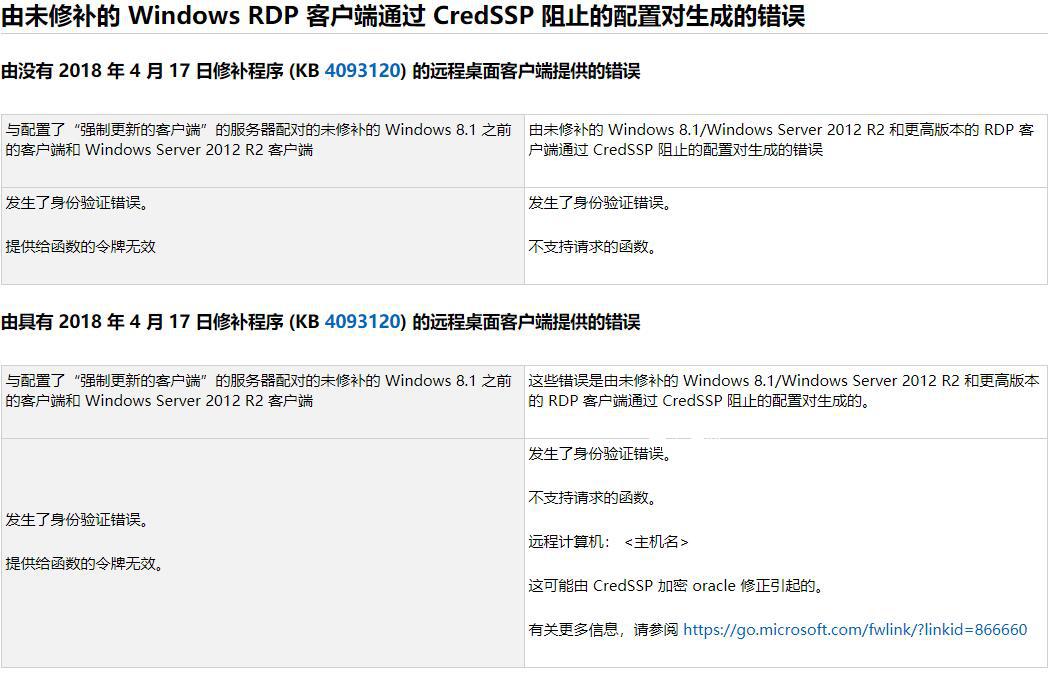
昨晚更新系统,更新完成后今天开机打开远程桌面意外却提示了 英文提示: An authentication error has occurred. The function requested is not supported Remote computer:xxx.xxx.xx This could be due to CredSSP encryption oracle remediation For more information, see https://go.microsoft.com/fwlink/?linkid=866660 中文提示: 经过查询资料得知 微软相关资料页面:点击访问 知道原因,问题就很好解决了,我们可以通过以下两种方法进行解决 1.如果可以直接访问,则只需在主机上通过安装对应的Windows 补丁即可解决 2.对于无法进行直接访问的,可以通过打开组策略(gpedit.msc),找到如下策略: 策略路径:“计算机配置”->“管理模板”->“系统”->“凭据分配” 英文版策略路径名称:“Computer Configuration”-> "Administrative Templates" -> "System" -> "Credentials Delegation" 设置名称: 加密 Oracle 修正 (Encryption Oracle Remediation) 默认为未配置,我们只需要将其改为已启用,防护级别改为“易受攻击”,应用并保存即可正常连接**ps:在Windows Server 2012 R2中已看不到此选项,建议尝试更新系统后再尝试,或也可尝试通过导入以下注册表尝试解决,如果仍旧无法解决,建议暂时通过修改系统属性中远程桌面的安全选项以解决连接问题注册表路径HKLM\Software\Microsoft\Windows\CurrentVersion\Policies\System\CredSSP\Parameters值AllowEncryptionOracle数据类型DWORD是否需要重启?是运行regedit打开注册表管理器。HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Policies\System\创建两级文件夹,也就是新建项。CredSSP\Parameters然后再Parameters下新建DWORD 32位,修改名称AllowEncryptionOracle。双击修改值为2.如觉得操作麻烦,也可直接导入以下注册表文件:注册表文件(本地下载) 注册表文件(云文件:0KB)附上KB4093120 官方下载地址:Microsoft Update Catalog
7388
相信很多和我一样的linux新手都会在安装linux后,输入命令下载文件,常常为输入一个长长的url地址而烦心吧。所以在安装linux后,第一步我们应该及时安装VMware Tools,这样会省不少事。好了,废话少说,开始进入正题吧:如何在Linux命令行模式下安装VMware Tools。选择菜单栏“虚拟机”——“安装VMware tools” ,等待系统自动更换ISO光盘**mount /dev/cdrom /mnt
cd /mnt
tar zxvf VMwareTools-9.6.0-1294478.tar.gz -C /root/(安装到的目录)
cd /root/
cd vmware-tools-distrib/
./vmware-install.pl最后,我们只需要一路回车到底,完成后重启系统。
6284
原文转自:http://k.sina.com.cn/article_1708729084_65d922fc0010065r5.html阿里资深无线开发专家李运华,系统梳理了自己的思考和理解,希望帮助更多同学少走一些弯路。不管是开发、测试、运维,每个技术人员心里多多少少都有一个成为技术大牛的梦,毕竟“梦想总是要有的,万一实现了呢”!正是对技术梦的追求,促使我们不断地努力和提升自己。然而“梦想是美好的,现实却是残酷的”,很多同学在实际工作后就会发现,梦想是成为大牛,但做的事情看起来跟大牛都不沾边。例如,程序员说“天天写业务代码还加班,如何才能成为技术大牛”,测试说“每天都有执行不完的测试用例”,运维说“扛机器接网线敲 Shell 命令,这不是我想要的运维人生”。我也是一位程序员,所以我希望通过以下基于程序开发的一些例子,帮助大家解决这些困惑。大道理是相通的,测试、运维都可以借鉴。几个典型的误区拜大牛为师有人认为想成为技术大牛最简单直接、快速有效的方式是“拜团队技术大牛为师”,让他们平时给你开小灶,给你分配一些有难度的任务。我个人是反对这种方法的,主要的原因有几个:大牛很忙,不太可能单独给你开小灶,更不可能每天都给你开 1 个小时的小灶。而且一个团队里面,如果大牛平时经常给你开小灶,难免会引起其他团队成员的疑惑,我个人认为如果团队里的大牛真正有心的话,多给团队培训是最好的。然而做过培训的都知道,准备一场培训是很耗费时间的,课件和材料至少 2 个小时(还不能是碎片时间),讲解 1 个小时,大牛们一个月做一次培训已经是很高频了。因为第一个原因,所以一般要找大牛,都是带着问题去请教或者探讨。因为回答或者探讨问题无需太多的时间,更多的是靠经验和积累,这种情况下大牛们都是很乐意的,毕竟影响力是大牛的一个重要指标嘛。然而也要特别注意:如果经常问那些书本或者 Google 能够很容易查到的知识,大牛们也会很不耐烦的,毕竟时间宝贵。经常有网友问我诸如“jvm 的 -Xmn 参数如何配置”这类问题,我都是直接回答“请直接去 Google”,因为这样的问题实在是太多了,如果自己不去系统学习,每个都要问是非常浪费自己和别人的时间的。大牛不多,不太可能每个团队都有技术大牛,只能说团队里面会有比你水平高的人,即使他每天给你开小灶,最终你也只能提升到他的水平。而如果是跨团队的技术大牛,由于工作安排和分配的原因,直接请教和辅导的机会是比较少的,单凭参加几次大牛的培训,是不太可能成为技术大牛的。综合上述的几个原因,我认为对于大部分人来说,要想成为技术大牛,首先还是要明白“主要靠自己”这个道理,不要期望有个像武功师傅一样的大牛手把手一步一步地教你。适当的时候可以通过请教大牛或者和大牛探讨来提升自己,但大部分时间还是自己系统性、有针对性的提升。业务代码一样很牛逼有人认为写业务代码一样可以很牛逼,理由是业务代码一样可以有各种技巧。例如可以使用封装和抽象使得业务代码更具可扩展性,可以通过和产品多交流以便更好的理解和实现业务,日志记录好了问题定位效率可以提升10倍等等。业务代码一样有技术含量,这点是肯定的,业务代码中的技术是每个程序员的基础,但只是掌握了这些技巧,并不能成为技术大牛。就像游戏中升级打怪一样,开始打小怪,经验值很高,越到后面经验值越少,打小怪已经不能提升经验值了,这个时候就需要打一些更高级的怪,刷一些有挑战的副本了,没看到哪个游戏只要一直打小怪就能升到顶级的。成为技术大牛的路也是类似的,你要不断的提升自己的水平,然后面临更大的挑战,通过应对这些挑战从而使自己水平更上一级,然后如此往复,最终达到技术大牛甚至业界大牛的境界。写业务代码只是这个打怪升级路上的一个挑战而已,而且我认为是比较初级的一个挑战。所以我认为:业务代码都写不好的程序员肯定无法成为技术大牛,但只把业务代码写好的程序员也还不能成为技术大牛。上班太忙没时间自己学习很多人认为自己没有成为技术大牛并不是自己不聪明,也不是自己不努力,而是在中国的这个环境下,技术人员加班都太多了,导致自己没有额外的时间进行学习。这个理由有一定的客观性,毕竟和欧美相比,我们的加班确实要多一些,但这个因素只是一个需要克服的问题,并不是不可逾越的鸿沟,毕竟我们身边还是有那么多的大牛也是在中国这个环境成长起来的。我认为有几个误区导致了这种看法的形成:上班做的都是重复工作,要想提升必须自己额外去学习。形成这个误区的主要原因还是在于认为“写业务代码是没有技术含量的”,而我现在上班就是写业务代码,所以我在工作中不能提升。学习需要大段的连续时间。很多人以为要学习就要像学校上课一样,给你一整天时间来上课才算学习,而我们平时加班又比较多,周末累的只想睡懒觉,或者只想去看看电影打打游戏来放松,所以就没有时间学习了。实际上的做法正好相反:首先我们应该在工作中学习和提升,因为学以致用或者有实例参考,学习的效果是最好的;其次工作后学习不需要大段时间,而是要挤出时间,利用时间碎片来学习。正确的做法Do more做的更多,做的比你主管安排给你的任务更多。我在 HW 的时候,负责一个版本的开发,这个版本的工作量大约是 2000 行左右。但是我除了做完这个功能,还将关联的功能全部掌握清楚了,代码(大约 10000 行)也全部看了一遍,做完这个版本后,我对这个版本相关的整套业务全部很熟悉了。经过一两次会议后,大家发现我对这块掌握最熟了,接下来就有趣了:产品讨论需求找我、测试有问题也找我、老大对外支撑也找我。后来,不是我负责的功能他们也找我,即使我当时不知道,我也会看代码或者找文档帮他们回答。最后我就成了我这个系统的“专家”了。虽然这个时候我还是做业务的,还是写业务代码,但是我已经对整个业务都很熟悉了。以上只是一个简单的例子,其实就是想说:要想有机会,首先你得从人群中冒出来,要想冒出来,你就必须做到与众不同,要做到与众不同,你就要做得更多!怎么做得更多呢?可以从以下几个方面着手:熟悉更多业务不管是不是你负责的,熟悉更多代码,不管是不是你写的,这样做有很多好处。举几个简单的例子:需求分析的时候更加准确,能够在需求阶段就识别风险、影响、难点。问题处理的时候更加快速,因为相关的业务和代码都熟悉,能够快速的判断问题可能的原因并进行排查处理。方案设计的时候考虑更加周全,由于有对全局业务的理解,能够设计出更好的方案。熟悉端到端比如说你负责 Web 后台开发,但实际上用户发起一个 HTTP 请求,要经过很多中间步骤才到你的服务器(例如浏览器缓存、DNS、Nginx 等)。服务器一般又会经过很多处理才到你写的那部分代码(路由、权限等),这整个流程中的很多系统或者步骤,绝大部分人是不可能去参与写代码的。但掌握了这些知识对你的综合水平有很大作用,例如方案设计、线上故障处理这些更加有含金量的技术工作都需要综合技术水平。“系统性”、“全局性”、“综合性”这些字眼看起来比较虚,但都是技术大牛必备的素质,要达到这样的境界,必须去熟悉更多系统、业务、代码。自学一般在比较成熟的团队,由于框架或者组件已经进行了大量的封装,写业务代码所用到的技术确实也比较少。但我们要明白“唯一不变的只有变化”,框架有可能要改进,组件可能要替换,或者你换了一家公司,新公司既没有组件也没有框架,要你从头开始来做。这些都是机会,也是挑战,而机会和挑战只会分配给有准备的人,所以这种情况下我们更加需要自学更多东西,因为真正等到要用的时候再来学已经没有时间了。以 Java 为例,大部分业务代码就是 if-else 加个数据库操作,但我们完全可以自己学些更多 Java 的知识。例如垃圾回收,调优,网络编程等,这些可能暂时没用,但真要用的时候,不是 Google 一下就可以了,这个时候谁已经掌握了相关知识和技能,机会就是谁的。以垃圾回收为例,我自己平时就抽时间学习了这些知识,学了 1 年都没用上,但后来用上了几次,每次都解决了卡死的大问题。而有的同学,写了几年的 Java 代码,对于 stop-the-world 是什么概念都不知道,更不用说去优化了。Do better要知道这个世界上没有完美的东西,你负责的系统和业务,总有不合理和可以改进的地方,这些“不合理”和“可改进”的地方,都是更高级别的怪物,打完后能够增加更多的经验值。识别出这些地方,并且给出解决方案,然后向主管提出,一次不行两次,多提几次,只要有一次落地了,这就是你的机会。例如:重复代码太多,是否可以引入设计模式?系统性能一般,可否进行优化?目前是单机,如果做成双机是否更好?版本开发质量不高,是否引入高效的单元测试和集成测试方案?目前的系统太庞大,是否可以通过重构和解耦改为 3 个系统?阿里中间件有一些系统感觉我们也可以用,是否可以引入 ?只要你去想,总能发现可以改进的地方的;如果你觉得系统哪里都没有改进的地方,那就说明你的水平还不够,可以多学习相关技术,多看看业界其他优秀公司怎么做。我 2013 年调配到九游,刚开始接手了一个简单的后台系统,每天就是配合前台做数据增删改查,看起来完全没意思,是吧?如果只做这些确实没意思,但我们接手后做了很多事情:解耦,将一个后台拆分为 2 个后台,提升可扩展性和稳定性。双机,将单机改为双机系统,提高可靠性。优化,将原来一个耗时 5 小时的接口优化为耗时 5 分钟。还有其他很多优化,后来我们这个组承担了更多的系统,也就是这个小组 5 个人,负责了 6 个系统。Do exercise在做职业等级沟通的时候,发现有很多同学确实也在尝试 Do more、Do better,但在执行的过程中,几乎每个人都遇到同一个问题:光看不用效果很差,怎么办?例如:学习了 Jvm 的垃圾回收,但是线上比较少出现 FGC 导致的卡顿问题,就算出现了,恢复业务也是第一位的,不太可能线上出现问题然后让每位同学都去练一下手,那怎么去实践这些 Jvm 的知识和技能呢?Netty 我也看了,也了解了 Reactor 的原理,但是我不可能参与 Netty 开发,怎么去让自己真正掌握 Reactor 异步模式呢?看了《高性能MySQL》,但是线上的数据库都是 DBA 管理的,测试环境的数据库感觉又是随便配置的,我怎么去验证这些技术呢?框架封装了 DAL 层,数据库的访问我们都不需要操心,我们怎么去了解分库分表实现?诸如此类问题还有很多,我这里分享一下个人的经验,其实就是 3 个词:learning、trying、teaching!Learning这个是第一阶段,看书、Google、看视频、看别人的博客都可以,但要注意一点是“系统化”,特别是一些基础性的东西,例如 Jvm 原理、Java 编程、网络编程,HTTP 协议等等。这些基础技术不能只通过 Google 或者博客学习,我的做法一般是先完整的看完一本书全面的了解,然后再通过 Google、视频、博客去有针对性的查找一些有疑问的地方,或者一些技巧。Trying这个步骤就是解答前面提到的很多同学的疑惑的关键点,形象来说就是“自己动手丰衣足食”,也就是自己去尝试搭建一些模拟环境,自己写一些测试程序。例如:Jvm 垃圾回收:可以自己写一个简单的测试程序,分配内存不释放,然后调整各种 jvm 启动参数,再运行的过程中使用 jstack、jstat 等命令查看 jvm 的堆内存分布和垃圾回收情况。这样的程序写起来很简单,简单一点的就几行,复杂一点的也就几十行。Reactor 原理:自己真正去尝试写一个 Reactor 模式的 Demo,不要以为这个很难,最简单的 Reactor 模式代码量(包括注释)不超过 200 行(可以参考 Doug Lee 的 PPT)。自己写完后,再去看看 Netty 怎么做,一对比理解就更加深刻了。MySQL:既然有线上的配置可以参考,那可以直接让 DBA 将线上配置发给我们(注意去掉敏感信息),直接学习。然后自己搭建一个 MySQL 环境,用线上的配置启动;要知道很多同学用了很多年 MySQL,但是连个简单的 MySQL 环境都搭不起来。框架封装了 DAL 层:可以自己用 JDBC 尝试去写一个分库分表的简单实现,然后与框架的实现进行对比,看看差异在哪里。用浏览器的工具查看 HTTP 缓存实现,看看不同种类的网站,不同类型的资源,具体是如何控制缓存的。也可以自己用 Python 写一个简单的 HTTP 服务器,模拟返回各种 HTTP Headers 来观察浏览器的反应。还有很多方法,这里就不一一列举,简单来说,就是要将学到的东西真正试试,才能理解更加深刻。印第安人有一句谚语:I hear and I forget. I see and I remember. I do and I understand ,而且“试试”可以比较简单,很多时候我们都可以自己动手做。当然,如果能够在实际工作中使用,效果会更好,毕竟实际的线上环境和业务复杂度不是我们写个模拟程序就能够模拟的。但这样的机会可遇不可求,大部分情况我们还真的只能靠自己模拟,然后等到真正业务要用的时候,能够信手拈来。Teaching一般来说,经过 Learning 和 Trying,能掌握 70% 左右,但要真正掌握,我觉得一定要做到能够跟别人讲清楚。因为在讲的时候,我们既需要将一个知识点系统化,也需要考虑各种细节,这会促使我们进一步思考和学习。同时,讲出来后看或者听的人可以有不同的理解,或者有新的补充,这相当于继续完善了整个知识技能体系。这样的例子很多,包括我自己写博客的时候经常遇到,本来我觉得自己已经掌握很全面了,但一写就发现很多点没考虑到。组内培训的时候也经常看到,有的同学写了 PPT,但是讲的时候,大家一问,或者一讨论,就会发现很多点还没有讲清楚,或者有的点其实是理解错了。写 PPT、讲 PPT、讨论 PPT,这个流程全部走一遍,基本上对一个知识点掌握就比较全面了。后记成为技术大牛梦想虽然很美好,但是要付出很多,不管是 Do more 还是 Do better 还是 Do exercise,都需要花费时间和精力,这个过程可能很苦逼,也可能很枯燥。这里我想特别强调一下:前面我讲的都是一些方法论的东西,但真正起决定作用的,其实还是我们对技术的热情和兴趣!作者:李运华编辑:陶家龙、孙淑娟来源:转载自阿里技术微信公众号
9430
原文地址:https://bbs.pediy.com/thread-225175.htm今天我们探索一个问题: 64位的ntdll是如何被加载到WoW64下的32位进程?今天的旅程将会带领我们进入到Windows内核逻辑中的未知领域,我们将会发现32位进程的内存地址空间是如何被初始化的。WoW64是什么?来自MSDN:WOW64是允许32位Windows应用程序无缝运行在64位Windows的模拟器。 换句话说,随着64位版本Windows的引进,Microsoft需要拿出一种允许在32位时代的Windows程序与64位Windows新的底层组件无缝交互的解决方案。特别是64位内存寻址和与内核直接交流的组件。两个NT层,一个内核在32位的Windows系统中,要调用Windows API的应用程序需要经过一系列的动态链接库(DLL)。然而,所有的系统调用最终会定向到ntdll.dll,它是在用户模式下将用户模式API传递给内核的最高层。以调用CreateFileW为例,这个API调用源于用户模式下的kernel32.dl,随后它以NtCreateFile传递给ntdll,随后NtCreateFile通过系统调度程序将控制权传递给内核。在32位Windows下这是非常简单的,然而,在WoW64下需要额外的步骤。32位的ntdll不可以直接将控制权交给内核,因为内核是64位的,只接受遵循64位ABI的类型(译者注:ABI,Application Binary Interface,应用二进制接口)。正因为如此,一个翻译层以几个标准的命名为wow64.dll,wow64cpu.dll和wow64win.dll的DLL的形式被添加到64位Windows。这几个DLL负责将32位调用转换成64位调用。那些调用最终被定向到映射到每个32位进程中的64位ntdll。许多关于这种从32位系统调用到64位系统调用(1)的神奇转换的信息是可获得的,所以我们不会从这里进入。我们最关注的是内核何时和怎样将64位版本的ntdll映射到一个32位进程。看起来像这样:我们特别关注倒数第二项。我们能发现ntdll被映射到地址是64位地址范围(7FFFFED40000-7FFFFEF1FFFF),而且它的位置在Windows 64位系统文件所在的System32\路径下。然而,我们知道32位进程不可以访问或者运行在64位内存空间。为了理解上面输出的内容,我们首先讨论VAD(Virtual Address Descriptor,虚拟地址描述符)是什么和它将如何帮助我们理解加载64位dll到32位进程的机制的。什么是虚拟地址描述符?VAD是Windows操作系统跟踪系统中可用物理内存的许多方法之一。VAD专门跟踪每个进程用户模式范围的保留的和提交的地址。任何时候一个进程请求一些内存,一个新的VAD实力被创建用来跟踪内存。VAD被构造成一个自平衡树,每个节点描述了一段内存范围。每个节点至多包含两个子节点,左边是低地址,右边是高地址。每个进程被分配一个VadRoot,之后通过遍历VadRoot来分辨额外用来描述保留或提交的虚拟地址范围的额外节点。我们需要关注WindDBG中的!vad命令的输出,因为这是我们将大量使用来跟踪64位Windows中32位进程的映射的输出。对于这个练习,不是所有的域对我们来说都是特别有趣的。我们考虑测试程序HelloWorld.exe的输出。通过!process ProcessObject 命令的输出来分辨我们进程的VadRoot。 一旦我们确定了VadRoot,我将地址输入到 !vad 命令。(输出为了容易分析已被截断)我们看到五列: "VAD", "Level", "Start", "End", 和"Commit".!vad命令 接受VAD实例的地址;在我们的例子中,我们已经为它提供了在此进程中通过使用!process命令获得的VadRoot。VAD地址是当前VAD结构体或实例的地址:等级(Level)描述了这个VAD实例(节点)在所在树中的级别。Level 0是从上面!process输出中获得的VadRoot。开始(Starting)和结束(Ending)地址值用VPN(Virtual Page Numbers,虚拟页数量)表示。这些地址可以通过乘以页面大小(4kb)或者左移3位转化为虚拟地址。结束VPN会添加一个额外的0xFFF来扩展到页面末尾。如我们上面例子中的D20->D20000,DD20->DD2FFF。提交(Commit)是被此VAD实例描述的范围内提交页面的数量。分配类型(type of allocation)告诉我们改特定范围是否已经被映射或是进程私有的。访问类型(Type of access)描述改范围内的允许访问。最后是被映射到当前区域对应的名称。一个AVD实例可以以多种方式创建。如通过使用映射API(CreateFileMapping/MapViewOfFile)或者内存分配API如VirutalAlloc函数。内存可以是保留或者提交的(或free的),或保留和部分提交的。无论哪一种,一个VAD项被映射到进程的Vad树来让内存管理器知道此进程中当前已提交的内存。我们对VAD 的观察将揭示WoW64下运行的32位进程的初始设置。 映射NT子系统DLL进程初始化的早期,在主可执行文件被映射和初始化之前,Windows为特殊区域确定和保留一些地址范围。其中包含初始进程地址空间,共享系统空间(_KUSER_SHARED_DATA),控制流守护位图区域,和NT本地子系统(ntdll)。由于进程初始化整体的复杂性,我们只关注最后一块,它包含32位ntdll和64位ntdll加载到32位进程地址空间的逻辑。我们关注一系列的API调用和在每个点的内存区域的虚拟地址描述符(VAD)。为了让内核区分怎样映射一个新进程,它需要知道是否这是一个WoW64进程。当进程对象最初被创建,内核通过读取名为_EPROCESS.Wow64Process的未文档化结构体_EPROCESS结构体的值来实现此操作。PspAllocateProcess是我们探索开始的地方,但是更具体的说,我们开始在MmInitializeProcessAddressSpace()。MmInitializeProcessAddressSpace()负责与一个新进程地址空间有关的初始化。它调用MiMapProcessExecutable,该函数创建了定义初始进程可寻址内存空间的VAD项,随后将新创建的进程映射到它的基虚拟地址。一个特别有趣的函数是PspMapSystemDlls。我们关注在调用PspMapSystemDlls之前的进程地址空间的样子。在WinDBG中确保我们当前处于我们测试应用程序的上下文中(.process),并寻找当前VadRoot(!vad output)。 到目前为止我们可以观察到,我们的进程在32问地址空间中被映射和分配了一个基地址(1200),内核共享内存(0x7FFE0000-0x7FFE0FFF) 和64KB保留内存区域(0x7FFE1000-0x7FFEFFFF) 也已经被映射到他们各自的虚拟地址。PspMapSystemDlls 通过一个包含多个平台子系统模块的全局指针迭代。对于x86和x64Windows,这些是分别位于 C:\Windows\SysWow64 和C:\Windows\System 目录中的ntdll.dll。一旦 PspMapSystemDlls 发现要加载的DLL,它调用 PspMapSystemDll 来映射他们(DLLs)到进程的地址空间。该函数非常简短,下面展示了一个片段。为了正确映射本地子系统,需要满足一些条件。 PspMapSystemDll 通过调用 MmMapViewOfSection 实现实际的本地DLL的映射,并保存所占的基地址。在这两个DLL映射完成并且他们的VAD项初始化完成后,我们的32位进程地址空间看起来像这样: 所以现在,我们映射完我们的进程(0xc40000-0xcf2fff),内核共享内存空间(0x7ffe0000-0x7ffe0fff),32位地址空间的有效结束区域(0x7ffe1000-0x7ffeffff),和我们的两个NT子系统DLL。锁定地址空间为了完成32位进程的映射,还有最后一步要做。我们知道一个32位进程最多寻址到2GB的虚拟内存,所以Windows需要屏蔽此进程剩余的地址空间。对于32位进程,屏蔽在 0x7FFF0000 - 0x7FFFFFFF 之后;然而,0x7FFeFFFF 之后什么也不可以映射。基于此事实,紧邻64位NTDLL的内存区域需要保留或者屏蔽。要做到这一点,内核标记剩下的64位地址空间为私有。它通过遍历当前进程的VAD树和定位最后可用的虚拟地址来创建此VAD项,然后附加一个新的VAD项。完成此任务的API是 MiInitializeUserNoAccess。该函数接受当前进程句柄和一个虚拟地址。传递的虚拟地址是 0x7FFF0000,这是32为进程最后可寻址范围的起始。然后,它遍历当前的VAD项并执行一个新范围的插入,该范围覆盖了32位进程剩余的地址空间。在此调用后,我们的进程地址空间看起来像这样: 我们现在可以发现,我们的32位进程已经映射,并且它的合规的内存地址范围已经被内核保留。涵盖 0x7FFF0 - 0x7FFFFED3F 和 0x7FFFFEF20- 0x7FFFFFFEF 范围的VAD实例已经被内核保留为私有。随后任何检索内存的调用仅仅会发生在允许的32为地址空间内。一旦进程完全加载,我们可以看到额外的已提交的内存出现在进程(0xC40000)附近的地址空间。 结束演讲我们观察到64位Windows下的32位进程的初始映射以及64位ntdll如何被映射到64位区域,随后64位地址空间被锁定,防止用户访问,我们学到了什么?1、早期初始化逻辑决定我们是否准备映射一个WoW64进程。2、分配最初的32位地址空间区域;这包括最高可访问的32位地址范围,和进程首选的基虚拟地址。3、NT子系统DLL被加载到他们各自的地址范围,32位ntdll加载到32位空间,64位ntdll加载到64位地址空间。4、MmInitializeUserNoAccess 用来创建与64位ntdll范围相邻的西游范围。这具有从32位进程锁定64位可寻址空间的效果。希望这篇文章提供了一些关于Windows如何允许讲32位进程无缝集成到64位Windows操作系统的透明度。随着WoW64模拟层的添加,对地址空间可用性进行了一些额外的考虑,并且这个过程反映了一些这些考虑和及其实现。
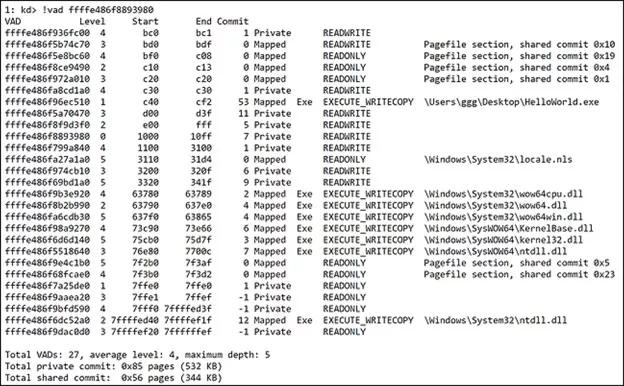
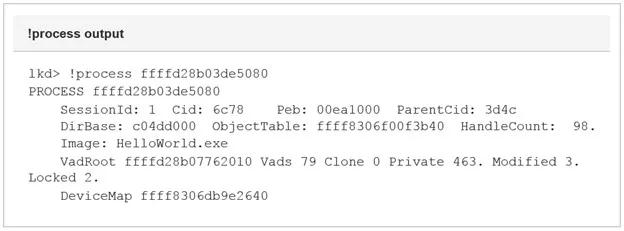
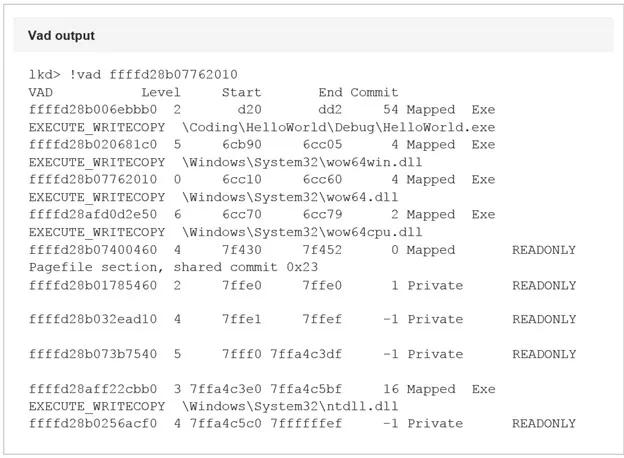
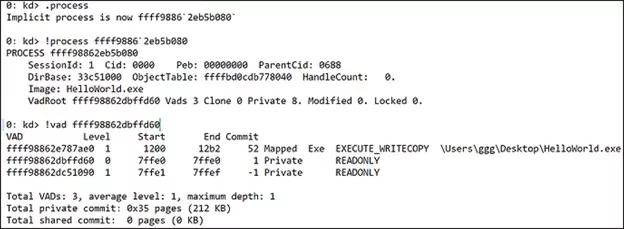
38500
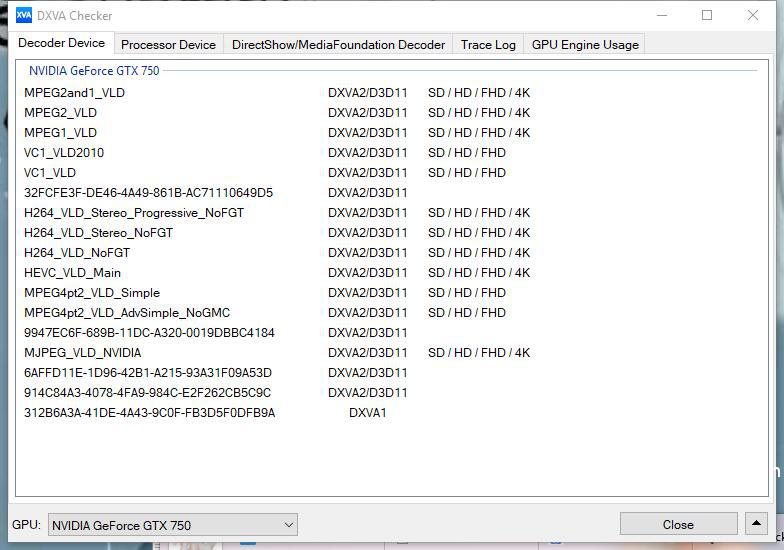
原文载自:http://www.hao4k.com/thread-9349-1-1.html 如果观看4K HDR视频和电影的时候,使用不正确的方法观看时,画面惨白惨白的,简直一塌糊涂,不知道人还以为是片源有问题呢。下面这图应该是很多用户会遇到的情况。HDR片源正确播放和非正确播放对比图。8 p3 a; N: q$ c: G4 N g 在开始介绍如何用PC播放HDR之前,小编还是建议大家花几百块买台电视盒子,这样省事儿很多。英特尔的牙膏还要一点一点挤,优秀的HDR算法更是捉襟见肘。相反ARM处理器就灵活很多,专门针对视频优化的ARM处理器甚至可以支持HDR10标准(12bit、Rec 2020、4K)的硬解。目前英特尔第七代U虽然支持了HEVC 4K 60FPS硬解,但是对于HDR的视频渲染目前还没有硬解方案。' H0 G, r) [0 L/ i6 Q电脑怎么播放4K HDR片子的方法(相关软件在文章最后均有提供): 2022.08.21 更新说明:如果使用的是完美解码带的potplayer,则已无需再进行设置,完美解码最新版本已自带Lentoid HEVC 渲染方案,最新版完美解码下载地址:完美解码 20220730 - 清新影视 (3vfree.cn) 下面小编介绍的方案是potplayerr播放器+madVR渲染。potplayer就不用过多介绍了,madVR支持读取片源里的HDR信息,然后把颜色重新映射在SDR屏幕上,模拟HDR的效果。& O! j+ { o/ E; c( ? 一、硬件检测 可以先用DXVAChecker检查一下CPU或者显卡是否支持HEVC 10bit硬解。站长用GTX750检查了一下,最高可以支持到4K HEVC 10bit硬件。 还有一点要注意,如果打算用PC输出到普通显示设备上观看HDR视频,那输出端口必须支持HDMI2.0和DP1.4,DP1.2的宽带虽然也够,但却不支持HDR/BT.2020。然而HD620核显HDMI只支持到了1.4,目前的4K电视是没有DP接口的,所以要借助转换器或者雷电接口了。打算拿Kaby Lake来做HTPC在电视上解码4K HDR视频的朋友,一定要留意HTPC是否有DP或雷电接口,4K电视是否有HDMI2.0接口。 大家可以去potplayerr官网和madVR官网分别下载最新的程序,安装完potplayerr之后记得勾选“安装额外的编解码器”,这样就可以将常用的解码器一并安装了。 二、madVR设置 madVR下载之后解压到非中文名称的路径下,管理员身份运行install.bat。这样madVR就安装好了。 接下来我们打开“madHcCtrl.exe”这个程序,对madVR进行简单设置,显示器设置选第二项Digital Monitor/TV。properties中,如果是PC就选0-255,如果是TV就选16-235。面板色数这里根据你自己面板的参数来,如果屏幕是8bit抖色成10bit且只能显示1670万色,那建议选8bit、9bit,这样色阶过度会好一点,不然画面可能会出现很多噪点或者断层。 calibration。选择第二项,表示显示器的色彩已经校准为BT.709(此处根据显示器色域性能选择不同的标准)。其他方面默认设置就好。 三、potplayerr设置 用potplayerr任意打开一个HDR视频,进入选项设置,在视频解码器中添加滤镜,选择系统滤镜,点选“madVR”(上图为具体操作流程)。这样播放器就成功添加了madVR滤镜。 接着把视频输出设备勾选为“Madshi视频渲染”,全屏独占模式选为“使用”(全屏下渲染更快)。至此视频渲染器的设置就完成了。]# g 四、效果检验 potplayerr播放界面下查看视频输出设备,出现了“Madshi视频渲染”。 快捷键Tab调出OSD信息可以看到视频渲染器为“Madshi Video Renderer”。 有木有感觉相当惊艳?!看到两种渲染模式的对比,HDR让人有种回到等离子时代的幻觉,而且这还是在普通显示器上演示的结果,如果放在峰值亮度1000nit及以上的显示设备上,那画面的真实感怕是要溢出了。 i 总结:由于HDR标准面世的时间还不太久,在消费领域推广HDR视频也是近几年才有的事情,所以市面上关于4K HDR的解决方案还并不是很多。本文介绍在PC端渲染的方法也还不尽完善,且对硬件要求非常之高。如果你打算更流畅的体验HDR带来的视觉惊喜,小编还是建议直接购买支持HDR的电视或者盒子。 HDR是为内容而生的,但是一个新技术面世初期,必然面临内容匮乏的尴尬。可这种尴尬并不能很快化解,因为内容创作是一次性的,越来越庞大的电视节目库不可能整体升级,可以期待的只是增量,只有新内容可以用更高的技术规格进行制作。短期内能做的只是通过现有片源+图像处理技术加以适当弥补。(完) 软件下载:①DXVA Check :点击下载 ②madVr :分卷1下载 分卷2下载 分卷3下载 分卷4下载 分卷5下载 附:完整madvr设置:点击查看(图片较大,如果显示不正常请刷新)


8018
转自:听雨轩有声电台 原文地址:http://mp.weixin.qq.com/s/TifDO-kE-yhxT3W9wdhCcg “即使是生活在阴沟,我们也有仰望星空的权利。”——阿米尔·汗 他的“仰望星空”,不是文艺青年的风花雪月。他用近乎残酷的方式,剖开印度的伤口,向国人和全世界展示社会的肮脏和弊病。01▼我喜欢一次只做一部电影为这一部倾尽所有一开始,阿米尔·汗并不喜欢电影,即便他出生在电影世家,且年幼成名。阿米尔·汗少年时其实极有运动天赋。那时的他热爱网球,不仅成为马哈拉施特拉邦的网球冠军,还与偶像费德勒打过友谊赛,梦想成为一枚网球小王子。但属于你的迟早会找上门。大学期间,阿米尔友情出演了一位朋友拍摄的无声小短片。大概是冥冥中的召唤,阿米尔说:“拍那部短片让我知道了自己属于那里”。于是毅然从学校辍学,一心投入演艺事业。然而,他的演艺之路走得却并不顺利。1988年,凭借电影《冷暖人间》,阿米尔汗一炮而红,并获得印度最高电影奖Filmfare的最佳新人奖。但接下来签下的九部电影都成绩寥寥。业界人士称他“只有一部电影的奇迹”,预测他将一蹶不振。阿米尔·汗开始在痛苦中自我反省,自我定位,要求自己每年作品绝不超过两部。“我喜欢一次只做一部电影,为这一部倾尽所有。”1992年开始,阿米尔·汗状态开始慢慢恢复。他对演戏的虔诚和认真甚至令人害怕。他曾经把四年时间花在一部戏上,就是《抗暴英雄》。兼为主演和制片人,他不停跑图书馆翻看历史资料,花了一年时间留起长发和八字胡。阿米尔·汗将自己视为“生产工具”,一丝不苟地表现电影的各种细节。和现在的演员喜欢用化妆不同,他电影中的每个样子,都是他本人的真实状态。在拍摄《摔跤吧!爸爸》的时候,先疯狂增肥60斤,再瘦回来,从19岁到51岁,他完美表现出了每一个阶段的体态变化。导演曾经劝他不要那么拼,化妆就好了。但他坚持成为一个真正的胖子:“只有成为胖子,我才能体会到胖子的感受。” 阿米尔·汗习惯在拍电影的时候写下“遗书”。甚至经常担心:如果我死了怎么办?如果我严重受伤怎么办?在每一场拍摄完成后,他会留给工作人员一个字条,上面写着万一他意外死亡,电影接下去的制作计划。在《摔跤吧!爸爸》拍摄期间,他甚至想好了四五个备选演员的名单。他有很好的电影嗅觉和商业眼光,拍出的电影总是叫好又叫座。接连刷新印度电影四个十亿级票房纪录。《摔跤吧,爸爸!》放映的时候,影片结束时,很多影院的观众全体起立,鼓掌致敬。但他却说自己拍电影之前从不想票房,也不会想有多少人去看。“故事是最重要的,如果我要拍一部电影,首先我一定要爱上这个故事,这样我才会有动力。” 也正是因为珍视初心,现如今阿米尔·汗几乎是与高质量电影画上了等号,有网友说:“阿米尔·汗的眼睛里有全世界,有他在,电影质量就有保证。”02▼我无心激化矛盾只为能改变这个时代红了之后的阿米尔·汗开始反思:“教师给社会提供教育,医生提供医疗,艺人能够给这个社会做些什么呢?”他决定用电影来改变世界。他好像带着天然的使命感,这种使命感,让他的电影充满力量。这一次,阿米尔·汗进入大众的视野,是因为《神秘巨星》。这部对准了妇女处境和妇女权益的电影,灵感来自于2012年阿米尔·汗系列节目《真相访谈》。在节目中,阿米尔·汗听到了一个女儿支持妈妈反抗的故事,直接激发了他拍摄《神秘巨星》的想法。在印度,妇女地位低下,每6小时就有一位妇女死于家暴。但印度社会却认为,丈夫殴打妻子,合情合理。但阿米尔·汗决心唤醒这些沉睡的人。从《摔跤吧,爸爸!》到《神秘巨星》,阿尔米·汗鼓励女性去做梦,去争取自己的权利。通过自己的力量,推动社会发生变化,用电影里的故事去影响别人,是阿米尔·汗的梦想。《摔跤吧,爸爸》《神秘巨星》中,他鼓励女性改变自身处境,主张自我权利,追求梦想:“你的胜利不只属于你,还属于千千万万被误解被歧视的女孩。”《三傻大闹宝莱坞》里,他向传统的应试教育发起了尖锐的挑战,告诉每一个人“死记硬背也许能让你通过大学4年,但会毁掉你接下来的40年”。通过《我滴个神啊》,他将宗教议题摆在了大屏幕,告诉大家“爱你,是要给你自由。”宗教也是。这部电影甚至冒犯了印度的政治团体,有印度教徒在公开场合焚烧海报,右翼人士抵制影片上映。阿米尔·汗一次又一次将印度的社会问题展现在大家面前。他明白,身为明星,担负着比别人更重的社会责任。一个人的力量是微小的,阿米尔汗却坚定不移。他深知自己的行为的意义:“我无心激化矛盾,只为能改变这个时代。无论是谁心中,只要有星星之火必将成燎原之势。”03▼没必要为自己祖国被放在聚光灯下而羞耻应该羞耻的是我们的国家在哪一方面有欠缺2012年,阿米尔·汗登上《时代周刊》亚洲版封面。评论写道:“他直面印度的社会弊病,打破了宝莱坞的固有模式,一个演员能够改变一个国家吗?”答案是肯定的。为了《真相访谈》,阿米尔·汗带领团队走访全国,儿童性侵、杀女婴、堕胎、包办婚姻、性别歧视、家庭暴力、种姓制度……这些敏感话题全都成为《真相访谈》的主题。当时很多身边的朋友都劝他:“你做这些对自己根本没好处,还会引起民众反感,降低你的人气。”阿米尔·汗在节目中自白:“我想讨论一些关系印度民生的话题,不责难任何人,不中伤任何人,也不制约任何人。人人都说,伤害我们的人近在咫尺,或许我们都有责任。”但节目一经播出,还是差点遭到印度当局的封禁,然而,仍然有超过6亿人观看了他的节目,他的每一期节目,都引起强烈社会反响和舆论关注,有人把这档节目叫做“印度的眼泪”。 在采访中,阿米尔·汗说:“我不知道这会不会影响到我的从影生涯,但是生而为人,我确实更关心我祖国的现状以及我同胞们的处境。这是一种选择,不是我们的义务,但是如果我们想这样,是可以做到的。”有人评价,阿米尔·汗是印度的“国宝级演员”。而在很多人的心中,阿米尔汗,早已不仅是一位演员。他的使命感和爱国精神,注定使他成为被这个时代铭记的人物。 2013年,阿米尔又作为“100位年度人物”再次登上《时代》封面,列入的并不是“艺术家”类别,而是定位为“先驱者”。这个头衔实至名归。因为他讲过这样的话:“拍摄电影不是用来迎合谁的。其实当你拍摄了一部对自己国家有一定批判意义的电影时,这对国家就有着至关重要的意义。所以批判自己和自己的国家是我们进步的第一步。没必要为自己祖国被放在聚光灯下而羞耻,应该羞耻的是我们的国家在哪一方面有欠缺。” 因为他,我们才知道,除了柴米油烟的生活之外,头顶还有一片浩瀚的星空;在个人的悲喜之外,人生还有更崇高的价值和意义需要守护。因为他,我们才知道,在这个时代,是多么需要阿米尔·汗这样的人。致敬阿米尔·汗。晚安文|崔老板


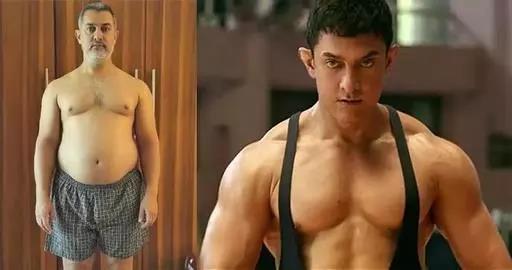

8315
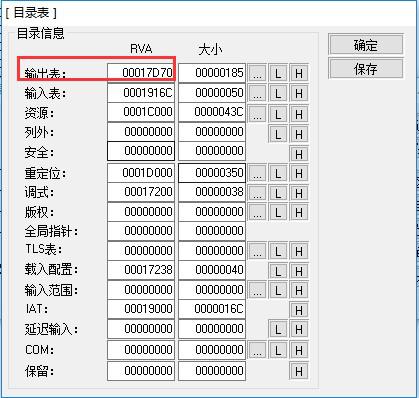
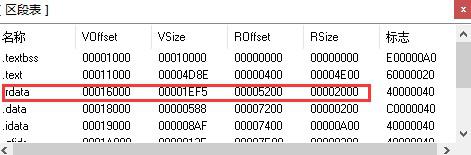
作者:Reginald 原文地址:https://bbs.pediy.com/thread-224265.htm一、导出表解析输出表位置,落在了.rdata段,16000【5200】17D70【6F70】从而,可以知道17D70,输出表在磁盘中的偏移是6F70在010里,Ctrl + G,输入6F70这里,先看下导出表的数据结构,40B,typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name; // DLL的名称地址
DWORD Base; // 索引基数
DWORD NumberOfFunctions; // 函数地址表大小
DWORD NumberOfNames; // 函数名表大小 == 函数序号表大小
DWORD AddressOfFunctions; // 函数地址表——首地址
DWORD AddressOfNames; // 函数名表——首地址
DWORD AddressOfNameOrdinals; // 函数序号表——首地址
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;那就从6F70的位置,开始,找40B,如下:00 00 00 0071 DB 67 5A 【时间戳】00 00 【主版本】00 00 【次版本】C0 7D 01 00【DLL名称地址】01 00 00 00 【索引基数】04 00 00 00 【函数地址表大小】04 00 00 00 【函数名表大小 == 函数序号表大小】98 7D 01 00【函数地址表——首地址】A8 7D 01 00 【函数名表——首地址】B8 7D 01 00【函数序号表——首地址】1、看DLL的名称是啥:地址17DC0【6FC0】,找到了我们自己的库dll_00.dll2、再看下函数地址表中的元素,首地址17D98【6F98】,共有4个,地址,4B/个如下所示:3、再来看函数名表中的元素,首地址17DA8【6FA8】,共有4个,地址4B/个这些都是地址值,要找到真正的函数名:17DD0【6FD0】17DD5【6FD5】17DDA【6FDA】17DCB【6FCB】特别注意:函数名表,其实存放的也是地址值,RVA,这个只是我们自己找到的名称,方便起见,直接写的名字4、接下来,看下函数序号表,首地址17DB8【6FB8】,4个,序号,2B/个5、接下来,就分析分析:从这里,也可以看到,序号表里的值,并没有加上索引基数最终,会得到如下结果:6、验证下,我们的结果:成功了;至于,索引基数,还没看到效果呢,————注意看下刚刚的LoadPe里的Ordinal那一列部分代码:#pragma once
#define WIN32DLL_EXPORTS
#ifdef __cplusplus
extern "C" {
#endif
#ifdef WIN32DLL_EXPORTS
#define WIN32DLL_API __declspec(dllexport)
#else
#define WIN32DLL_API __declspec(dllimport)
#endif
WIN32DLL_API void Fun1();
WIN32DLL_API void Fun2();
WIN32DLL_API void Fun3();
#ifdef __cplusplus
}
#endifdef文件LIBRARY;
EXPORTS;
Fun4;二、导入表解析写一个测试程序,查看导入表RVA输入表位置,落在了.idata段1A000【7400】1A1E8【75E8】共20Btypedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not
DWORD ForwarderChain;
DWORD Name;
DWORD FirstThunk; // RVA to IAT
} IMAGE_IMPORT_DESCRIPTOR;2C A3 01 00 【OriginalFirstThunk:INT(Import Name Table)导入名称表地址RVA】00 00 00 00 00 00 00 00 54 A4 01 00【DLL名称(地址值)】E0 A0 01 00【IAT(Import Address Table)导入地址表地址RVA】1、首先看下DLL的名字,1A454【7854】2、看下INT(OriginalFirstThunk):1A32C【772C】,全0结尾函数名数组:44 A4 01 00 ————1A444【7844】——————最高位为0,说明是名称导入的,不是序号导入的;3C A4 01 00 ————1A43C【783C】——————4C A4 01 00 ————1A44C【784C】——————34 A4 01 00 ————1A434【7834】——————注意:IAT和INT都指向下面的数据结构,4Btypedef struct _IMAGE_THUNK_DATA32 {
union {
DWORD ForwarderString; // PBYTE
DWORD Function; // PDWORD,导入函数的地址,在加载到内存后,这里才起作用
DWORD Ordinal; // 假如是序号导入的,会用到这里
DWORD AddressOfData; // PIMAGE_IMPORT_BY_NAME,假如是函数名导入的,用到这里,它指向另外一个结构体:PIMGE_IMPORT_BY_NAME
} u1;
} IMAGE_THUNK_DATA32;
// 如果是函数名导入的,AddressOfData会指向下面这个结构体
typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint;
CHAR Name[1];
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;由上可知,函数名导入的,因此,上面的地址值,就会指向一个PIMAGE_IMPORT_BY_NAME的结构体:【7844】Fun3【783C】Fun2【784C】Fun4【7834】Fun13、看下IAT,1A0E0【74E0】全0结束,IAT和INT一样,都指向IMAGE_THUNK_DATA32结构体,4B可见,最高位都是0,所以,也是名称导入的,另外,还可以发现,这个位置的值,和INT的值是一样的,因此,不再赘述了;44 A4 01 00 3C A4 01 00 4C A4 01 00 34 A4 01 00#include <stdio.h>
extern "C" __declspec(dllimport) void Fun1();
extern "C" __declspec(dllimport) void Fun2();
extern "C" __declspec(dllimport) void Fun3();
// 如果是在def中导出的,需要如下声明
void Fun4();
#pragma comment(lib, "../Debug/dll_00.lib")
int main(int argc, char** argv) {
Fun1();
Fun2();
Fun3();
Fun4();
getchar();
return 0;
}三、如果,修改def为LIBRARY;
EXPORTS;
Fun4 @1;看下导入表里的INT/IAT:可见,这里的一项,最高位为1,序号导入,这个序号,就是dll export的那个序号至此,PE结构中,导入/导出表的介绍结束;PS:I Dare to do sth I feared,作为一枚奋斗青年,也是一枚小白,最近在学习PE结构相关的知识,这篇帖子也算是自己的一个总结;希望能对需要的人以帮助;也期待大神们的更多指导;


7878
DBA操作规范作者:hcymysql 原文转自:http://blog.51cto.com/hcymysql/20614511、涉及业务上的修改/删除数据,在得到业务方、CTO的邮件批准后方可执行,执行前提前做好备份,必要时可逆。2、所有上线需求必须走工单系统,口头通知视为无效。3、在对大表做表结构变更时,如修改字段属性会造成锁表,并会造成从库延迟,从而影响线上业务,必须在凌晨0:00 后业务低峰期执行,另统一用工具 pt-online-schema-change 避免锁表且降低延迟执行时间。使用范例:#pt-online-schema-change --alter="add index IX_id_no(id_no)" \
--no-check-replication-filters --recursion-method=none --user=dba \
--password=123456 D=test,t=t1 --execute对于MongoDB创建索引要在后台创建,避免锁表。使用范例:db.t1.createIndex({idCardNum:1},{background:1})4、所有线上业务库均必须搭建MHA高可用架构,避免单点问题。5、给业务方开权限时,密码要用MD5加密,至少16位。权限如没有特殊要求,均为select查询权限,并做库表级限制。6、删除默认空密码账号。delete from mysql.user where user='' and password='';
flush privileges;7、汇总库开启Audit审计日志功能,出现问题时方可追溯。行为规范8、禁止一个MySQL实例存放多个业务数据库,会造成业务耦合性过高,一旦出现问题会殃及池鱼,增加了定位故障问题的难度。通常采用多实例解决,一个实例一个业务库,互不干扰。9、禁止在主库上执行后台管理和统计类的功能查询,这种复杂类的SQL会造成CPU的升高,进而会影响业务。10、批量清洗数据,需要开发和DBA共同进行审查,应避开业务高峰期时段执行,并在执行过程中观察服务状态。11、促销活动等应提前与DBA当面沟通,进行流量评估,比如提前一周增加机器内存或扩展架构,防止DB出现性能瓶颈。12、禁止在线上做数据库压力测试。基本规范13、禁止在数据库中存储明文密码。14、使用InnoDB存储引擎。支持事务,行级锁,更好的恢复性,高并发下性能更好。InnoDB表避免使用COUNT(*)操作,因内部没有计数器,需要一行一行累加计算,计数统计实时要求较强可以使用memcache或者Redis。15、表字符集统一使用UTF8。不会产生乱码风险。16、所有表和字段都需要添加中文注释。方便他人、方便自己。17、不在数据库中存储图片、文件等大数据。图片、文件更适合于GFS分布式文件系统,数据库里存放超链接即可。18、避免使用存储过程、视图、触发器、事件。MySQL是OLTP应用,最擅长简单的增、删、改、查操作,但对逻辑计算分析类的应用,并不适合,所以这部分的需求最好通过程序上实现。19、避免使用外键,外键用来保护参照完整性,可在业务端实现。外键会导致父表和子表之间耦合,十分影响SQL性能,出现过多的锁等待,甚至会造成死锁。20、对事务一致性要求不高的业务,如日志表等,优先选择存入MongoDB。其自身支持的sharding分片功能,增强了横向扩展的能力,开发不用过多调整业务代码。库表设计规范21、表必须有主键,例如自增主键。这样可以保证数据行是按照顺序写入,对于SAS传统机械式硬盘写入性能更好,根据主键做关联查询的性能也会更好,并且还方便了数据仓库抽取数据。从性能的角度来说,使用UUID作为主键是个最不好的方法,它会使插入变得随机。22、禁止使用分区表。分区表的好处是对于开发来说,不用修改代码,通过后端DB的设置,比如对于时间字段做拆分,就可以轻松实现表的拆分。但这里面涉及一个问题,查询的字段必须是分区键,否则会遍历所有的分区表,并不会带来性能上的提升。此外,分区表在物理结构上仍旧是一张表,此时我们更改表结构,一样不会带来性能上的提升。所以应采用切表的形式做拆分,如程序上需要对历史数据做查询,可通过union all的方式关联查询。另外随着时间的推移,历史数据表不再需要,只需在从库上dump出来,即便捷地迁移至备份机上。字段设计规范23、用DECIMAL代替FLOAT和DOUBLE存储精确浮点数。浮点数的缺点是会引起精度问题,请看下面一个例子:mysql> CREATE TABLE t3 (c1 float(10,2),c2 decimal(10,2));
Query OK, 0 rows affected (0.05 sec)
>mysql> insert into t3 values (999998.02, 999998.02);
Query OK, 1 row affected (0.01 sec)
>mysql> select * from t3;
+-----------+-----------+
| c1 | c2 |
+-----------+-----------+
| 999998.00 | 999998.02 |
+-----------+-----------+
1 row in set (0.00 sec)可以看到c1列的值由999998.02变成了999998.00,这就是float浮点数类型的不精确性造成的。因此对货币等对精度敏感的数据,应该用定点数表示或存储。24、使用TINYINT来代替ENUM类型。采用enum枚举类型,会存在扩展的问题,例如用户在线状态,如果此时增加了:5表示请勿打扰、6表示开会中、7表示隐身对好友可见,那么增加新的ENUM值要做DDL修改表结构操作了。25、字段长度尽量按实际需要进行分配,不要随意分配一个很大的容量。选择字段的一般原则是保小不保大,能用占用字节少的字段就不用大字段。比如主键,强烈建议用int整型,不用uuid,为什么?省空间啊。空间是什么?空间就是效率!按4个字节和按32个字节定位一条记录,谁快谁慢太明显了。涉及几个表做join时,效果就更明显了。更小的字段类型占用的内存就更少,占用的磁盘空间和磁盘I/O也会更少,而且还会占用更少的带宽。有不少开发人员在设计表字段时,只要是针对数值类型的全部用int,但这不一定合适,就比如用户的年龄,一般来说,年龄大都在1~100岁之间,长度只有3,那么用int就不适合了,可以用tinyint代替。又比如用户在线状态,0表示离线、1表示在线、2表示离开、3表示忙碌、4表示隐身等,其实类似这样的情况,用int都是没有必要的,浪费空间,采用tinyint完全可以满足需要,int占用的是4字节,而tinyint才占用1个字节。int整型有符号(signed)最大值是2147483647,而无符号(unsigned)最大值是4294967295,如果你的需求没有存储负数,那么建议改成有符号(unsigned),可以增加int存储范围。int(10)和int(1)没有什么区别,10和1仅是宽度而已,在设置了zerofill扩展属性的时候有用,例:root@localhost(test)10:39>create table test(id int(10) zerofill,id2 int(1));
Query OK, 0 rows affected (0.13 sec)
root@localhost(test)10:39>insert into test values(1,1);
Query OK, 1 row affected (0.04 sec)
root@localhost(test)10:56>insert into test values(1000000000,1000000000);
Query OK, 1 row affected (0.05 sec)
root@localhost(test)10:56>select * from test;
+------------+------------+
| id | id2 |
+------------+------------+
| 0000000001 | 1 |
| 1000000000 | 1000000000 |
+------------+------------+
2 rows in set (0.01 sec)26、字段定义为NOT NULL要提供默认值。从应用层角度来看,可以减少程序判断代码,比如你要查询一条记录,如果没默认值,你是不是得先判断该字段对应变量是否被设置,如果没有,你得通过java把该变量置为''或者0,如果设了默认值,判断条件可直接略过。NULL值很难进行查询优化,它会使索引统计更加复杂,还需要MySQL内部进行特殊处理。27、尽可能不使用TEXT、BLOB类型。增加存储空间的占用,读取速度慢。索引规范28、索引不是越多越好,按实际需要进行创建。索引是一把双刃剑,它可以提高查询效率但也会降低插入和更新的速度并占用磁盘空间。适当的索引对应用的性能至关重要,而且在MySQL中使用索引它的速度是极快的。遗憾的是,索引也有相关的开销。每次向表中写入时(如INSERT、UPDATEH或DELETE),如果带有一个或多个索引,那么MySQL也要更新各个索引,这样索引就增加了对各个表的写入操作的开销。只有当某列被用于WHERE子句时,才能享受到索引的性能提升的好处。如果不使用索引,它就没有价值,而且会带来维护上的开销。29、查询的字段必须创建索引。如:1、SELECT、UPDATE、DELETE语句的WHERE条件列;2、多表JOIN的字段。30、不在索引列进行数学运算和函数运算。无法使用索引,导致全表扫描。例:SELECT * FROM t WHERE YEAR(d) >= 2016;由于MySQL不像Oracle那样支持函数索引,即使d字段有索引,也会直接全表扫描。应改为----->SELECT * FROM t WHERE d >= '2016-01-01';31、不在低基数列上建立索引,例如‘性别’。有时候,进行全表浏览要比必须读取索引和数据表更快,尤其是当索引包含的是平均分布的数据集是更是如此。对此典型的例子是性别,它有两个均匀分布的值(男和女)。通过性别需要读取大概一半的行。在种情况下进行全表扫描浏览要更快。32、不使用%前导的查询,如like ‘%xxx’。无法使用索引,导致全表扫描。低效查询
SELECT * FROM t WHERE name LIKE '%de%';
----->
高效查询
SELECT * FROM t WHERE name LIKE 'de%';33、不使用反向查询,如 not in / not like。无法使用索引,导致全表扫描。34、避免冗余或重复索引。联合索引IX_a_b_c(a,b,c) 相当于 (a) 、(a,b) 、(a,b,c),那么索引 (a) 、(a,b) 就是多余的。SQL设计规范*35、不使用SELECT ,只获取必要的字段。**消耗CPU和IO、消耗网络带宽;无法使用覆盖索引。36、用IN来替换OR。低效查询
SELECT * FROM t WHERE LOC_ID = 10 OR LOC_ID = 20 OR LOC_ID = 30;
----->
高效查询
SELECT * FROM t WHERE LOC_IN IN (10,20,30);37、避免数据类型不一致。SELECT * FROM t WHERE id = '19';
----->
SELECT * FROM t WHERE id = 19;38、减少与数据库的交互次数。INSERT INTO t (id, name) VALUES(1,'Bea');
INSERT INTO t (id, name) VALUES(2,'Belle');
INSERT INTO t (id, name) VALUES(3,'Bernice');
----->
INSERT INTO t (id, name) VALUES(1,'Bea'), (2,'Belle'),(3,'Bernice');
Update … where id in (1,2,3,4);
Alter table tbl_name add column col1, add column col2;39、拒绝大SQL,拆分成小SQL。低效查询
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id = tag.id
JOIN post ON tag_post.post_id = post.id
WHERE tag.tag = 'mysql';
可以分解成下面这些查询来代替
----->
高效查询
SELECT * FROM tag WHERE tag = 'mysql'
SELECT * FROM tag_post WHERE tag_id = 1234
SELECT * FROM post WHERE post_id in (123, 456, 567, 9098, 8904);40、禁止使用order by rand()SELECT * FROM t1 WHERE 1=1 ORDER BY RAND() LIMIT 4;
---->
SELECT * FROM t1 WHERE id >= CEIL(RAND()*1000) LIMIT 4;
8706
本文转载自差评(ID:chaping321) 网址:点击访问差友们,平时上网最讨厌看到啥?差评君觉得,应该是这货没啥争议 ↓↓这几乎是互联网时兴以来,每个人都无法避免会遇到的问题。404 这三个数字好像网络之神赐给每个信众的礼物~无论你是亿万富翁还是国家总统,网页打不开就是打不开,啥招也没用。。神说,要有 404,于是有了。。可是,为什么网页打不开,网页上都会显示 404 呢?传说,互联的发明者蒂姆·伯纳斯-李( Tim Berners-Lee )曾经在瑞士的欧洲核研究组织的 404 房间办公,在这个 404 房间有互联网时代的第一个服务器,人们所有的网络请求都会发向那里。大型强子对撞机就是这个欧洲核研究组织的如果你要访问的网络内容不存在,那个服务器就会给你返回 404 Not Found( 404 找不到资源)。。也不知道这个来由是从哪冒出来的,反正越传越广,最后连互联网的发明者罗伯特·卡利奥(Robert Cailliau)都不得不站出来澄清:造谣也要遵循基本法好吧,404 就是因为按顺序轮到 404 了而已。。其实,现在互联网网页都遵循 HTTP 协议(HyperText Transfer Protocol,超文本传输协议),我们每个人需求的网页内容都存储在一个个服务器上,这些储存着 HTML 文件和图像。当服务器检测到有用户给它发送打开网页的请求,服务器就会返回给那个用户一些东西,包括网页状态以及返回的内容(如请求的文件、错误消息、或者其它信息)。一个 HTTP 响应示例上面这个图,就是一个 HTTP 返回的例子,那个红框框起来的,里面有一个东西叫做 “ 返回状态码 ”,这个返回状态码就代表了这个网页状态。譬如,这个例子的网站的返回码是 200,也就是说,这个网站能够被成功访问~2XX 的返回码表示网页请求成功估计大家也看到了,4 开头的状态码就是错误码,返回 4XX 的,这个网页肯定打不开~404 就是其中一种错误的代号。。当服务器找不到用户请求的网页数据,而且并不知道错误原因,才会显示返回一个 404。出现 404 错误之后,网页显示什么内容,全看状态后面跟着什么消息体(看上面倒数第三个图)。有的网站就写着 “ 网页找不到 ”,而有的网站就会埋一些彩蛋~Magic Leap 的 404 网站去年 9 月有网友发现,在 Magic Leap 写着 “ 错误 404 ” 的页面上,一个电灯泡闪烁的频率为摩斯密码,破译后得出的结果正好是鲸鱼座中一颗星星的准确坐标,而这颗星星在每年12月时最明显,网友得出结论: Magic Leap 产品可能会在 12 月正式亮相!果然,Magic Leap 在去年 12 月发布了第一款产品。。(这特么也可以??)那网页出现 404 就一定是因为服务器无法找到用户请求么?天真!也有可能服务器了解你的请求,服务器也有相应的内容,但由于某种奇怪的原因,它被禁止回应你的请求。这时候本来服务器应该回一个 403 和无法返回数据请求的原因,但是它肯定不想被你发现它故意不给你数据,所以,它很有可能就回你一个 404 Not Found,假装自己没有这个数据。。RFC2616 HTTP/1.1 协议里关于 403 的描述不只是 403 ,还有 500 (服务器遇到意外情况,unexpected condition..),都有可能因为服务器懒得跟你解释发生错误的原因,就干脆甩给你一个 404 错误。。是不是突然想明白好多事?就像前面说的一样, 404 只是 HTTP 协议里面的一种返回码,这些返回码能让开发者知道网络连接错误的原因。如果你想在国内看 YouTube 等网站,浏览器会显示 “ 无法访问此网站 ”这种情况下,我们根本无法连接到相应的服务器上,连返回的状态码都没有。。这个完全可以通过浏览器自带的开发者工具看出来~打个比方,使用不了谷歌好像是你的电话线被拔了,电话根本打不出去;而 404 好比是你电话打出去了,可是那头跟你反馈用户无法接通。。所以说上不了谷歌和 404 压根一点关系都没有,是你的网不够科学~HTTP 协议里一共规定了 66 个标准 HTTP 状态返回码,每个都有自己的场景应用,可是有一个是异类。。418 返回码! I'm a teapot?我是个茶壶??WTF??其实,这是 1998 年愚人节的时候发布的一个搞笑 RFC 协议(RFC 2324 - Hyper Text Coffee Pot Control Protocol (HTCPCP/1.0)),超文本咖啡壶控制协议。里面主要围绕一个论题展开:虽然咖啡无处不在,但如果你给一个茶壶发送泡咖啡的请求,那肯定是不行的。。鬼知道这些程序员都在想些什么奇怪的东西。。。如果你一定要给茶壶发送这个请求,茶壶就会给你返回一个 “ I'm a teapot ” 的错误码 418 ,表示我只是一个茶壶,并不能泡咖啡~就这么一个愚人节玩笑,那帮技术宅居然一本正经的写了 10 页文档(网址在这,自己戳:https://tools.ietf.org/html/rfc2324)。。更骚的是,他们还出了续集。。因为之前那个 RFC 2324 超文本咖啡壶控制协议只描写了对咖啡壶的规范,这对只喝茶的人赤裸裸的歧视!所以,2014 年愚人节,他们又发布了 RFC 7168(The Hyper Text Coffee Pot Control Protocol for Tea Efflux Appliances),超文本咖啡壶控制协议之茶版本扩展。就喜欢你们一本正经的胡说八道的样子里面详细的描述了如何使用联网设备,实践各种各样复杂的茶冲泡工艺。连里边放的调味种类分类都细致的不行。。差评君服了。。只提一个小小的建议,貌似这里冲茶的工艺有些偏西方,大部分中国人是没有在茶里面放糖的习惯,所以我建议对泡茶种类做一个划分,什么铁观音、大红袍、普洱之类的。今年愚人节再出一个补充版吧~有人问了, HTTP 返回码就已知的那么几个么?当然不是了。。其实只要程序员有心,他可以自己自定义好多非标准的返回码,只要客户端和服务端都认识就行。当然,国内经常见到的这种图。。这个吧,是你搜的东西不够科学~