

7202

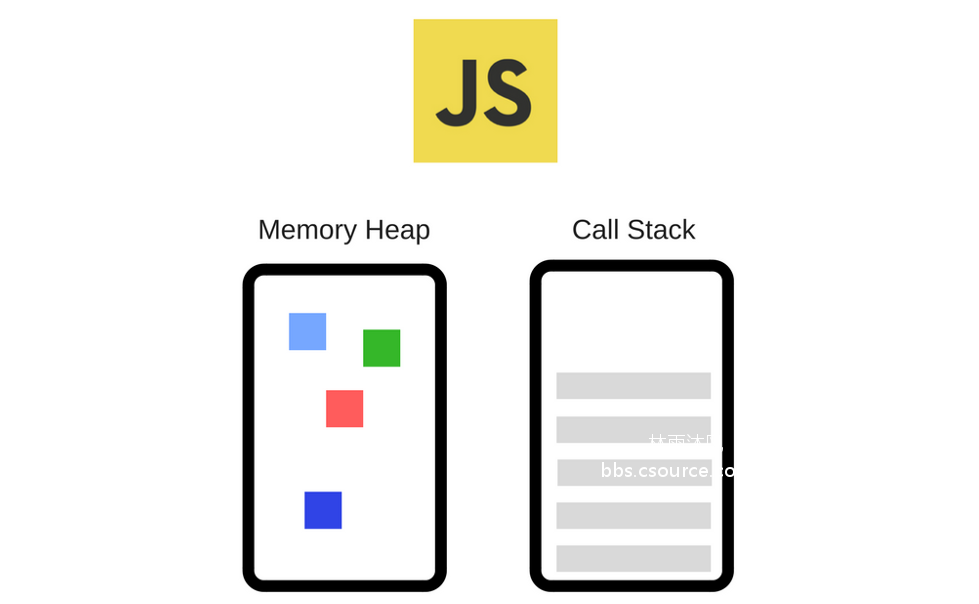
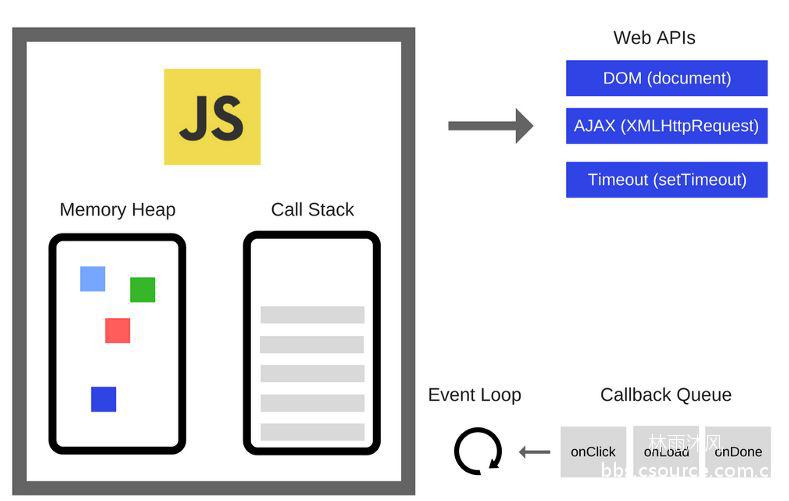
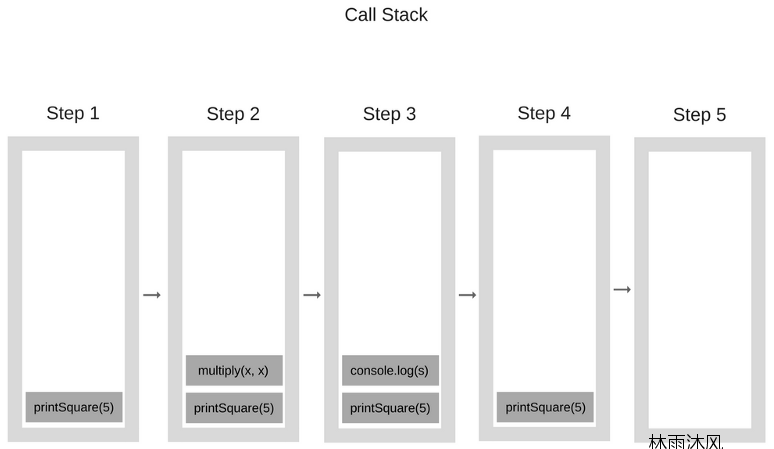
作者:Ox9A82 转自看雪论坛 原文地址:http://mp.weixin.qq.com/s/8lXtiwq5BO6PeXlFT57R7gQJavascript语言现在变得越来越流行,各个团队利用了它在各种层面上的支持特性,比如前端、后端、混合的应用程序、嵌入式设备等等。 这篇文章作为这一系列文章的第一篇,旨在深挖 Javascript 的底层工作原理:我们认为通过了解 Javascript 的构建块以及了解它们是怎么一起工作的可以使得我们写出更好的代码和app。我们还将分享构建 SessionStack 时的一些经验法则,这是一个轻量级的 JavaScript 应用程序,它必须保持强大且高性能才能保持竞争力。 如GitHut统计中所示,JavaScript在GitHub中的活动存储库和总推送量方面位居前列。相比其他类别也不落后。如果项目越来越依赖于JavaScript,这意味着开发人员必须利用语言和生态系统提供的所有内容,深入了解内部,才能构建出令人惊叹的软件。 事实证明,有很多开发人员每天都在使用JavaScript,但并不知道底层会发生什么。概览几乎每个人都听说过V8引擎这个概念,大多数人都知道JavaScript是单线程的,或者它使用的是回调队列。在这篇文章中,我们将详细介绍所有这些概念,并解释JavaScript如何运行。通过了解这些细节,您将能够编写更好的非阻塞应用程序,并且学会正确使用所提供的API。 如果你对JavaScript比较陌生,那么这篇博文将帮助你理解为什么说JavaScript与其他语言相比是比较怪异的。 如果你是一位经验丰富的JavaScript开发人员,我希望能够提供一些关于你每天都在使用的JavaScript Runtime的实际工作情况的全新理解。Javascript引擎关于JS引擎一个最著名的例子就是谷歌的V8引擎。目前Chrome和Node.js中使用的就是V8引擎。下面是一个简单的视图:引擎包含两个主要部件:堆内存 - 这是发生内存分配的地方调用栈 - 这是代码执行时的栈帧运行时几乎所有的JS开发者在浏览器中都使用过API(例如“setTimeout”)。但是,这些API不是由引擎提供的。 那么这些API从哪里来呢? 事实证明,现实情况有些复杂。如图所示,可以发现其实我们除了引擎之外还依赖其他很多东西。像DOM、AJAX、setTimeout等等这些东西是由浏览器提供的,被称为Web API。 然后,我们就有了非常流行的事件循环和回调队列。调用栈JavaScript是一种单线程语言,这意味着它只有一个调用栈。因此,它同一时间只可以做一件事。调用栈是一个数据结构,它大致的记录了我们位于程序中的哪个位置。 如果我们进入一个函数,就会把它放在栈的顶部。如果我们从一个函数返回,那么会弹出栈的顶部。 我们来看一个例子。如下面的代码:function multiply(x, y) {
return x * y;
}
function printSquare(x) {
var s = multiply(x, x);
console.log(s);
}
printSquare(5);当引擎开始执行这段代码之前,调用栈是空的。之后的步骤如下:调用栈中的每个条目都称为是栈帧。 这也是在发生异常时进行堆栈跟踪的方法 - 这大体上是异常发生时的调用栈的状态。看看下面的代码:function foo() {
throw new Error('SessionStack will help you resolve crashes :)');
}
function bar() {
foo();
}
function start() {
bar();
}
start();如果这是在Chrome中执行的(假设代码在一个名为foo.js的文件中),那么会产生下面的堆栈跟踪:“栈上溢(Blowing the stack)” - 当达到最大调用栈大小时就会发生这种情况。 这可能会很容易的发生,特别是使用递归的情况下。看看这个示例代码:function foo() {
foo();
}
foo();当引擎开始执行这个代码时,它首先调用函数“foo”。然而,这个函数是递归的,并且没有任何终止条件。 所以在执行的步骤中,同一个函数会一次又一次地添加到调用栈中。 它看起来像这样:在某些情况下,调用栈中函数调用的数量超出了调用栈的实际大小,浏览器通过抛出一个错误(如下所示)来采取行动:在单线程上运行代码可能会更容易一些,因为不必担心多线程环境中出现的复杂场景,例如死锁。 但是在单线程上运行也是非常有限的。 由于JS只有一个调用栈,所以当运行很慢时会发生什么?并发和事件循环如果在调用栈中的函数调用需要花费大量时间才能进行处理,会发生什么? 例如,假设你想在浏览器中使用JS进行一些复杂的图像转换。 你可能会奇怪 - 为什么这是个问题?但是问题是,虽然调用栈有执行的功能,但此时浏览器实际上不能做其他的任何事情 - 它被阻塞了。 这意味着浏览器无法进行渲染,也不能运行任何其他代码,它只是卡住了。 如果你想在你的应用程序中实现流畅的UI,这就会产生问题。 并且这还不是唯一的问题。 一旦浏览器开始在调用栈中处理如此多的任务,它可能会停止响应相当长的时间。 而且大多数浏览器会通过抛出错误来应对,询问是否要终止网页。所以这不是一个好的用户体验,是吗? 那么,我们如何执行大量代码而不会阻塞UI使浏览器无法响应呢?解决方案是异步回调。这将在“JavaScript底层是如何工作的”教程的第2部分中更详细地解释。 同时,如果在JS应用遇到了难以复制和理解问题,请查看SessionStack。 SessionStack记录Web应用程序中的所有内容:所有的DOM更改,用户交互,JavaScript异常,堆栈跟踪,失败的网络请求和调试消息。借助SessionStack,可以将视频中的问题重放为视频,并查看用户发生的所有事情。

3
0 3110天前
6451
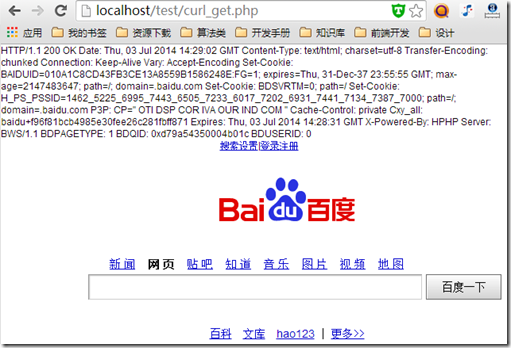
一、什么是CURL?cURL 是一个利用URL语法规定来传输文件和数据的工具,支持很多协议,如HTTP、FTP、TELNET等。最爽的是,PHP也支持 cURL 库。使用PHP的cURL库可以简单和有效地去抓网页。你只需要运行一个脚本,然后分析一下你所抓取的网页,然后就可以以程序的方式得到你想要的数据了。无论是你想从从一个链接上取部分数据,或是取一个XML文件并把其导入数据库,那怕就是简单的获取网页内容,cURL 是一个功能强大的PHP库。二、CURL函数库。curl_close — 关闭一个curl会话curl_copy_handle — 拷贝一个curl连接资源的所有内容和参数curl_errno — 返回一个包含当前会话错误信息的数字编号curl_error — 返回一个包含当前会话错误信息的字符串curl_exec — 执行一个curl会话curl_getinfo — 获取一个curl连接资源句柄的信息curl_init — 初始化一个curl会话curl_multi_add_handle — 向curl批处理会话中添加单独的curl句柄资源curl_multi_close — 关闭一个批处理句柄资源curl_multi_exec — 解析一个curl批处理句柄curl_multi_getcontent — 返回获取的输出的文本流curl_multi_info_read — 获取当前解析的curl的相关传输信息curl_multi_init — 初始化一个curl批处理句柄资源curl_multi_remove_handle — 移除curl批处理句柄资源中的某个句柄资源curl_multi_select — Get all the sockets associated with the cURL extension, which can then be “selected”curl_setopt_array — 以数组的形式为一个curl设置会话参数curl_setopt — 为一个curl设置会话参数curl_version — 获取curl相关的版本信息curl_init()函数的作用初始化一个curl会话,curl_init()函数唯一的一个参数是可选的,表示一个url地址。curl_exec()函数的作用是执行一个curl会话,唯一的参数是curl_init()函数返回的句柄。curl_close()函数的作用是关闭一个curl会话,唯一的参数是curl_init()函数返回的句柄。三、PHP建立CURL请求的基本步骤①:初始化curl_init()②:设置属性curl_setopt().有一长串cURL参数可供设置,它们能指定URL请求的各个细节。③:执行并获取结果curl_exec()④:释放句柄curl_close()四、CURL实现GET和POST①:GET方式实现<?php
//初始化
$curl = curl_init();
//设置抓取的url
curl_setopt($curl, CURLOPT_URL, 'http://www.baidu.com');
//设置头文件的信息作为数据流输出
curl_setopt($curl, CURLOPT_HEADER, 1);
//设置获取的信息以文件流的形式返回,而不是直接输出。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
//执行命令
$data = curl_exec($curl);
//关闭URL请求
curl_close($curl);
//显示获得的数据
print_r($data);
?>运行结果:②:POST方式实现<?php
//初始化
$curl = curl_init();
//设置抓取的url
curl_setopt($curl, CURLOPT_URL, 'http://www.baidu.com');
//设置头文件的信息作为数据流输出
curl_setopt($curl, CURLOPT_HEADER, 1);
//设置获取的信息以文件流的形式返回,而不是直接输出。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
//设置post方式提交
curl_setopt($curl, CURLOPT_POST, 1);
//设置post数据
$post_data = array(
"username" => "coder",
"password" => "12345"
);
curl_setopt($curl, CURLOPT_POSTFIELDS, $post_data);
//执行命令
$data = curl_exec($curl);
//关闭URL请求
curl_close($curl);
//显示获得的数据
print_r($data);
?>③:如果获得的数据时json格式的,使用json_decode函数解释成数组。$output_array = json_decode($output,true);如果使用json_decode($output)解析的话,将会得到object类型的数据。五、我自己封装的一个函数//参数1:访问的URL,参数2:post数据(不填则为GET),参数3:提交的$cookies,参数4:是否返回$cookies
function curl_request($url,$post='',$cookie='', $returnCookie=0){
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_USERAGENT, 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)');
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($curl, CURLOPT_AUTOREFERER, 1);
curl_setopt($curl, CURLOPT_REFERER, "http://XXX");
if($post) {
curl_setopt($curl, CURLOPT_POST, 1);
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));
}
if($cookie) {
curl_setopt($curl, CURLOPT_COOKIE, $cookie);
}
curl_setopt($curl, CURLOPT_HEADER, $returnCookie);
curl_setopt($curl, CURLOPT_TIMEOUT, 10);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$data = curl_exec($curl);
if (curl_errno($curl)) {
return curl_error($curl);
}
curl_close($curl);
if($returnCookie){
list($header, $body) = explode("\r\n\r\n", $data, 2);
preg_match_all("/Set\-Cookie:([^;]*);/", $header, $matches);
$info['cookie'] = substr($matches[1][0], 1);
$info['content'] = $body;
return $info;
}else{
return $data;
}
}附可选参数说明:第一类:对于下面的这些option的可选参数,value应该被设置一个bool类型的值:选项可选value值备注CURLOPT_AUTOREFERER当根据Location:重定向时,自动设置header中的Referer:信息。CURLOPT_BINARYTRANSFER在启用CURLOPT_RETURNTRANSFER的时候,返回原生的(Raw)输出。CURLOPT_COOKIESESSION启用时curl会仅仅传递一个session cookie,忽略其他的cookie,默认状况下cURL会将所有的cookie返回给服务端。session cookie是指那些用来判断服务器端的session是否有效而存在的cookie。CURLOPT_CRLF启用时将Unix的换行符转换成回车换行符。CURLOPT_DNS_USE_GLOBAL_CACHE启用时会启用一个全局的DNS缓存,此项为线程安全的,并且默认启用。CURLOPT_FAILONERROR显示HTTP状态码,默认行为是忽略编号小于等于400的HTTP信息。CURLOPT_FILETIME启用时会尝试修改远程文档中的信息。结果信息会通过 curl_getinfo()函数的CURLINFO_FILETIME选项返回。curl_getinfo().CURLOPT_FOLLOWLOCATION启用时会将服务器服务器返回的”Location: “放在header中递归的返回给服务器,使用CURLOPT_MAXREDIRS可以限定递归返回的数量。CURLOPT_FORBID_REUSE在完成交互以后强迫断开连接,不能重用。CURLOPT_FRESH_CONNECT强制获取一个新的连接,替代缓存中的连接。CURLOPT_FTP_USE_EPRT启用时当FTP下载时,使用EPRT (或 LPRT)命令。设置为FALSE时禁用EPRT和LPRT,使用PORT命令 only.CURLOPT_FTP_USE_EPSV启用时,在FTP传输过程中回复到PASV模式前首先尝试EPSV命令。设置为FALSE时禁用EPSV命令。CURLOPT_FTPAPPEND启用时追加写入文件而不是覆盖它。CURLOPT_FTPASCIICURLOPT_TRANSFERTEXT的别名。CURLOPT_FTPLISTONLY启用时只列出FTP目录的名字。CURLOPT_HEADER启用时会将头文件的信息作为数据流输出。CURLINFO_HEADER_OUT启用时追踪句柄的请求字符串。从 PHP 5.1.3 开始可用。CURLINFO_前缀是故意的(intentional)。CURLOPT_HTTPGET启用时会设置HTTP的method为GET,因为GET是默认是,所以只在被修改的情况下使用。CURLOPT_HTTPPROXYTUNNEL启用时会通过HTTP代理来传输。CURLOPT_MUTE启用时将cURL函数中所有修改过的参数恢复默认值。CURLOPT_NETRC在连接建立以后,访问~/.netrc文件获取用户名和密码信息连接远程站点。CURLOPT_NOBODY启用时将不对HTML中的BODY部分进行输出。CURLOPT_NOPROGRESS启用时关闭curl传输的进度条,此项的默认设置为启用。Note:PHP自动地设置这个选项为TRUE,这个选项仅仅应当在以调试为目的时被改变。CURLOPT_NOSIGNAL启用时忽略所有的curl传递给php进行的信号。在SAPI多线程传输时此项被默认启用。cURL 7.10时被加入。CURLOPT_POST启用时会发送一个常规的POST请求,类型为:application/x-www-form-urlencoded,就像表单提交的一样。CURLOPT_PUT启用时允许HTTP发送文件,必须同时设置CURLOPT_INFILE和CURLOPT_INFILESIZE。CURLOPT_RETURNTRANSFER将 curl_exec()获取的信息以文件流的形式返回,而不是直接输出。CURLOPT_SSL_VERIFYPEER禁用后cURL将终止从服务端进行验证。使用CURLOPT_CAINFO选项设置证书使用CURLOPT_CAPATH选项设置证书目录 如果CURLOPT_SSL_VERIFYPEER(默认值为2)被启用,CURLOPT_SSL_VERIFYHOST需要被设置成TRUE否则设置为FALSE。自cURL 7.10开始默认为TRUE。从cURL 7.10开始默认绑定安装。CURLOPT_TRANSFERTEXT启用后对FTP传输使用ASCII模式。对于LDAP,它检索纯文本信息而非HTML。在Windows系统上,系统不会把STDOUT设置成binary模式。CURLOPT_UNRESTRICTED_AUTH在使用CURLOPT_FOLLOWLOCATION产生的header中的多个locations中持续追加用户名和密码信息,即使域名已发生改变。CURLOPT_UPLOAD启用后允许文件上传。CURLOPT_VERBOSE启用时会汇报所有的信息,存放在STDERR或指定的CURLOPT_STDERR中。第二类:对于下面的这些option的可选参数,value应该被设置一个integer类型的值:选项可选value值备注CURLOPT_BUFFERSIZE每次获取的数据中读入缓存的大小,但是不保证这个值每次都会被填满。在cURL 7.10中被加入。CURLOPT_CLOSEPOLICY不是CURLCLOSEPOLICY_LEAST_RECENTLY_USED就是CURLCLOSEPOLICY_OLDEST,还存在另外三个CURLCLOSEPOLICY_,但是cURL暂时还不支持。CURLOPT_CONNECTTIMEOUT在发起连接前等待的时间,如果设置为0,则无限等待。CURLOPT_CONNECTTIMEOUT_MS尝试连接等待的时间,以毫秒为单位。如果设置为0,则无限等待。在cURL 7.16.2中被加入。从PHP 5.2.3开始可用。CURLOPT_DNS_CACHE_TIMEOUT设置在内存中保存DNS信息的时间,默认为120秒。CURLOPT_FTPSSLAUTHFTP验证方式:CURLFTPAUTH_SSL (首先尝试SSL),CURLFTPAUTH_TLS (首先尝试TLS)或CURLFTPAUTH_DEFAULT (让cURL自动决定)。在cURL 7.12.2中被加入。CURLOPT_HTTP_VERSIONCURL_HTTP_VERSION_NONE (默认值,让cURL自己判断使用哪个版本),CURL_HTTP_VERSION_1_0 (强制使用 HTTP/1.0)或CURL_HTTP_VERSION_1_1 (强制使用 HTTP/1.1)。CURLOPT_HTTPAUTH使用的HTTP验证方法,可选的值有:CURLAUTH_BASIC、CURLAUTH_DIGEST、CURLAUTH_GSSNEGOTIATE、CURLAUTH_NTLM、CURLAUTH_ANY和CURLAUTH_ANYSAFE。可以使用|位域(或)操作符分隔多个值,cURL让服务器选择一个支持最好的值。CURLAUTH_ANY等价于CURLAUTH_BASIC | CURLAUTH_DIGEST | CURLAUTH_GSSNEGOTIATE | CURLAUTH_NTLM.CURLAUTH_ANYSAFE等价于CURLAUTH_DIGEST | CURLAUTH_GSSNEGOTIATE | CURLAUTH_NTLM.CURLOPT_INFILESIZE设定上传文件的大小限制,字节(byte)为单位。CURLOPT_LOW_SPEED_LIMIT当传输速度小于CURLOPT_LOW_SPEED_LIMIT时(bytes/sec),PHP会根据CURLOPT_LOW_SPEED_TIME来判断是否因太慢而取消传输。CURLOPT_LOW_SPEED_TIME当传输速度小于CURLOPT_LOW_SPEED_LIMIT时(bytes/sec),PHP会根据CURLOPT_LOW_SPEED_TIME来判断是否因太慢而取消传输。CURLOPT_MAXCONNECTS允许的最大连接数量,超过是会通过CURLOPT_CLOSEPOLICY决定应该停止哪些连接。CURLOPT_MAXREDIRS指定最多的HTTP重定向的数量,这个选项是和CURLOPT_FOLLOWLOCATION一起使用的。CURLOPT_PORT用来指定连接端口。(可选项)CURLOPT_PROTOCOLSCURLPROTO_*的位域指。如果被启用,位域值会限定libcurl在传输过程中有哪些可使用的协议。这将允许你在编译libcurl时支持众多协议,但是限制只是用它们中被允许使用的一个子集。默认libcurl将会使用全部它支持的协议。参见CURLOPT_REDIR_PROTOCOLS.可用的协议选项为:CURLPROTO_HTTP、CURLPROTO_HTTPS、CURLPROTO_FTP、CURLPROTO_FTPS、CURLPROTO_SCP、CURLPROTO_SFTP、CURLPROTO_TELNET、CURLPROTO_LDAP、CURLPROTO_LDAPS、CURLPROTO_DICT、CURLPROTO_FILE、CURLPROTO_TFTP、CURLPROTO_ALL在cURL 7.19.4中被加入。CURLOPT_PROXYAUTHHTTP代理连接的验证方式。使用在CURLOPT_HTTPAUTH中的位域标志来设置相应选项。对于代理验证只有CURLAUTH_BASIC和CURLAUTH_NTLM当前被支持。在cURL 7.10.7中被加入。CURLOPT_PROXYPORT代理服务器的端口。端口也可以在CURLOPT_PROXY中进行设置。CURLOPT_PROXYTYPE不是CURLPROXY_HTTP (默认值) 就是CURLPROXY_SOCKS5。在cURL 7.10中被加入。CURLOPT_REDIR_PROTOCOLSCURLPROTO_*中的位域值。如果被启用,位域值将会限制传输线程在CURLOPT_FOLLOWLOCATION开启时跟随某个重定向时可使用的协议。这将使你对重定向时限制传输线程使用被允许的协议子集默认libcurl将会允许除FILE和SCP之外的全部协议。这个和7.19.4预发布版本种无条件地跟随所有支持的协议有一些不同。关于协议常量,请参照CURLOPT_PROTOCOLS。在cURL 7.19.4中被加入。CURLOPT_RESUME_FROM在恢复传输时传递一个字节偏移量(用来断点续传)。CURLOPT_SSL_VERIFYHOST1 检查服务器SSL证书中是否存在一个公用名(common name)。译者注:公用名(Common Name)一般来讲就是填写你将要申请SSL证书的域名 (domain)或子域名(sub domain)。2 检查公用名是否存在,并且是否与提供的主机名匹配。CURLOPT_SSLVERSION使用的SSL版本(2 或 3)。默认情况下PHP会自己检测这个值,尽管有些情况下需要手动地进行设置。CURLOPT_TIMECONDITION如果在CURLOPT_TIMEVALUE指定的某个时间以后被编辑过,则使用CURL_TIMECOND_IFMODSINCE返回页面,如果没有被修改过,并且CURLOPT_HEADER为true,则返回一个”304 Not Modified”的header, CURLOPT_HEADER为false,则使用CURL_TIMECOND_IFUNMODSINCE,默认值为CURL_TIMECOND_IFUNMODSINCE。CURLOPT_TIMEOUT设置cURL允许执行的最长秒数。CURLOPT_TIMEOUT_MS设置cURL允许执行的最长毫秒数。在cURL 7.16.2中被加入。从PHP 5.2.3起可使用。CURLOPT_TIMEVALUE设置一个CURLOPT_TIMECONDITION使用的时间戳,在默认状态下使用的是CURL_TIMECOND_IFMODSINCE。第三类:对于下面的这些option的可选参数,value应该被设置一个string类型的值:选项可选value值备注CURLOPT_CAINFO一个保存着1个或多个用来让服务端验证的证书的文件名。这个参数仅仅在和CURLOPT_SSL_VERIFYPEER一起使用时才有意义。 .CURLOPT_CAPATH一个保存着多个CA证书的目录。这个选项是和CURLOPT_SSL_VERIFYPEER一起使用的。CURLOPT_COOKIE设定HTTP请求中”Cookie: “部分的内容。多个cookie用分号分隔,分号后带一个空格(例如, “fruit=apple; colour=red”)。CURLOPT_COOKIEFILE包含cookie数据的文件名,cookie文件的格式可以是Netscape格式,或者只是纯HTTP头部信息存入文件。CURLOPT_COOKIEJAR连接结束后保存cookie信息的文件。CURLOPT_CUSTOMREQUEST使用一个自定义的请求信息来代替”GET”或”HEAD”作为HTTP请求。这对于执行”DELETE” 或者其他更隐蔽的HTTP请求。有效值如”GET”,”POST”,”CONNECT”等等。也就是说,不要在这里输入整个HTTP请求。例如输入”GET /index.html HTTP/1.0\r\n\r\n”是不正确的。Note:在确定服务器支持这个自定义请求的方法前不要使用。CURLOPT_EGDSOCKET类似CURLOPT_RANDOM_FILE,除了一个Entropy Gathering Daemon套接字。CURLOPT_ENCODINGHTTP请求头中”Accept-Encoding: “的值。支持的编码有”identity”,”deflate”和”gzip”。如果为空字符串””,请求头会发送所有支持的编码类型。在cURL 7.10中被加入。CURLOPT_FTPPORT这个值将被用来获取供FTP”POST”指令所需要的IP地址。”POST”指令告诉远程服务器连接到我们指定的IP地址。这个字符串可以是纯文本的IP地址、主机名、一个网络接口名(UNIX下)或者只是一个’-’来使用默认的IP地址。CURLOPT_INTERFACE网络发送接口名,可以是一个接口名、IP地址或者是一个主机名。CURLOPT_KRB4LEVELKRB4 (Kerberos 4) 安全级别。下面的任何值都是有效的(从低到高的顺序):”clear”、”safe”、”confidential”、”private”.。如果字符串和这些都不匹配,将使用”private”。这个选项设置为NULL时将禁用KRB4 安全认证。目前KRB4 安全认证只能用于FTP传输。CURLOPT_POSTFIELDS全部数据使用HTTP协议中的”POST”操作来发送。要发送文件,在文件名前面加上@前缀并使用完整路径。这个参数可以通过urlencoded后的字符串类似’para1=val1¶2=val2&…’或使用一个以字段名为键值,字段数据为值的数组。如果value是一个数组,Content-Type头将会被设置成multipart/form-data。CURLOPT_PROXYHTTP代理通道。CURLOPT_PROXYUSERPWD一个用来连接到代理的”[username]:[password]“格式的字符串。CURLOPT_RANDOM_FILE一个被用来生成SSL随机数种子的文件名。CURLOPT_RANGE以”X-Y”的形式,其中X和Y都是可选项获取数据的范围,以字节计。HTTP传输线程也支持几个这样的重复项中间用逗号分隔如”X-Y,N-M”。CURLOPT_REFERER在HTTP请求头中”Referer: “的内容。CURLOPT_SSL_CIPHER_LIST一个SSL的加密算法列表。例如RC4-SHA和TLSv1都是可用的加密列表。CURLOPT_SSLCERT一个包含PEM格式证书的文件名。CURLOPT_SSLCERTPASSWD使用CURLOPT_SSLCERT证书需要的密码。CURLOPT_SSLCERTTYPE证书的类型。支持的格式有”PEM” (默认值), “DER”和”ENG”。在cURL 7.9.3中被加入。CURLOPT_SSLENGINE用来在CURLOPT_SSLKEY中指定的SSL私钥的加密引擎变量。CURLOPT_SSLENGINE_DEFAULT用来做非对称加密操作的变量。CURLOPT_SSLKEY包含SSL私钥的文件名。CURLOPT_SSLKEYPASSWD在CURLOPT_SSLKEY中指定了的SSL私钥的密码。Note:由于这个选项包含了敏感的密码信息,记得保证这个PHP脚本的安全。CURLOPT_SSLKEYTYPECURLOPT_SSLKEY中规定的私钥的加密类型,支持的密钥类型为”PEM”(默认值)、”DER”和”ENG”。CURLOPT_URL需要获取的URL地址,也可以在 curl_init()函数中设置。CURLOPT_USERAGENT在HTTP请求中包含一个”User-Agent: “头的字符串。CURLOPT_USERPWD传递一个连接中需要的用户名和密码,格式为:”[username]:[password]“。第四类对于下面的这些option的可选参数,value应该被设置一个数组:选项可选value值备注CURLOPT_HTTP200ALIASES200响应码数组,数组中的响应吗被认为是正确的响应,否则被认为是错误的。在cURL 7.10.3中被加入。CURLOPT_HTTPHEADER一个用来设置HTTP头字段的数组。使用如下的形式的数组进行设置: array(‘Content-type: text/plain’, ‘Content-length: 100′)CURLOPT_POSTQUOTE在FTP请求执行完成后,在服务器上执行的一组FTP命令。CURLOPT_QUOTE一组先于FTP请求的在服务器上执行的FTP命令。对于下面的这些option的可选参数,value应该被设置一个流资源 (例如使用 fopen()):选项可选value值CURLOPT_FILE设置输出文件的位置,值是一个资源类型,默认为STDOUT (浏览器)。CURLOPT_INFILE在上传文件的时候需要读取的文件地址,值是一个资源类型。CURLOPT_STDERR设置一个错误输出地址,值是一个资源类型,取代默认的STDERR。CURLOPT_WRITEHEADER设置header部分内容的写入的文件地址,值是一个资源类型。对于下面的这些option的可选参数,value应该被设置为一个回调函数名:选项可选value值CURLOPT_HEADERFUNCTION设置一个回调函数,这个函数有两个参数,第一个是cURL的资源句柄,第二个是输出的header数据。header数据的输出必须依赖这个函数,返回已写入的数据大小。CURLOPT_PASSWDFUNCTION设置一个回调函数,有三个参数,第一个是cURL的资源句柄,第二个是一个密码提示符,第三个参数是密码长度允许的最大值。返回密码的值。CURLOPT_PROGRESSFUNCTION设置一个回调函数,有三个参数,第一个是cURL的资源句柄,第二个是一个文件描述符资源,第三个是长度。返回包含的数据。CURLOPT_READFUNCTION拥有两个参数的回调函数,第一个是参数是会话句柄,第二是HTTP响应头信息的字符串。使用此函数,将自行处理返回的数据。返回值为数据大小,以字节计。返回0代表EOF信号。CURLOPT_WRITEFUNCTION拥有两个参数的回调函数,第一个是参数是会话句柄,第二是HTTP响应头信息的字符串。使用此回调函数,将自行处理响应头信息。响应头信息是整个字符串。设置返回值为精确的已写入字符串长度。发生错误时传输线程终止。本文链接:http://www.blogfshare.com/php-curl-get-post.html
2
0 3114天前
8796
原文地址:http://blog.csdn.net/ibingow/article/details/7104346 经常碰到某些程序崩溃时弹出带红色叉叉的错误窗口或者是叫你选择调试或关闭的窗口,很碍眼。不过平时也没去理它,点掉就好。 今天客户反映我们的程序崩溃后就起不来了,其实我们为了方便无人化管理,做了一个守护进程。如果程序异常退出就会重启那个程序,这在linux下没问题,程序崩溃了就直接退出返回非零值,但是window就bug了,搞不好就给你弹出个错误对话框,你不点掉其实程序就没退出,守护进程就不知道这个程序是否崩溃,于是这个程序就永远死在那个窗口上了。现在这不仅碍眼,还碍事!于是着手摆平之。 先是晚上搜到可以修改注册表来组织程序或系统的弹出对话框,参考:http://technet.microsoft.com/en-us/library/cc976167.aspx。不过这不可行,我们只是希望我们的程序不会弹出对话框,尽量少改系统的。而且试了下发现还是会弹出来,就是那个werfault.exe进程,xp下可能不会。算了,这条路不走了。 用代码肯定也有办法解决。你看人家qq什么的奔溃了有弹出的都是自家的温馨提示,我们不需要温馨提示,只要返回非零值就好。 万能的Google一下子就搜出结果来了。原来Microsoft对c和c++进行了扩展,支持异常处理,而且貌似标准c++里的异常处理也是它的一个封装。Microsoft的异常处理函数是__try,__except。先试了这么个简单的例子 #include <windows.h>
#include <excpt.h>
#include <stdio.h>
#define CRASH_SILENTLY 1
#if defined(_MSC_VER) && CRASH_SILENTLY
#include <excpt.h>
#define Q_TRY_BEGIN __try {
#define Q_TRY_END }
//EXCEPTION_EXECUTE_HANDLER
#define Q_EXCEPT __except(EXCEPTION_EXECUTE_HANDLER) { \
printf("Shit happens!\n");fflush(NULL); \
return 1;}
#else
#define Q_TRY_BEGIN
#define Q_TRY_END
#define Q_EXCEPT
#endif
int main(int, char**)
{
Q_TRY_BEGIN
int *a = 0;
*a = 0;
Q_TRY_END
Q_EXCEPT
printf("Exiting 0...\n");
fflush(NULL);
return 0;
}
如果把CRASH_SILENTLY定义为0,那么在程序崩溃就会弹出对话框,设为一就只打印Shit happens!然后就返回。 __except的参数有三种,详细内容见http://msdn.microsoft.com/en-us/library/s58ftw19%28v=vs.80%29.aspx,我就不抄了。 其实为什么系统会弹出这么一个对话框呢?其实在vc运行库中顶层函数也用了__try, __except的异常捕获机制。不知您看了__except的参数了没,我的示例程序里是EXCEPTION_EXECUTE_HANDLER,表示异常被识别,就在__except后面的代码段进行异常处理。如果是EXCEPTION_CONTINUE_SEARCH,那么异常会继续被派发到外层,这最外层就是vc库,vc库它的处理手段就是碍眼又碍事的对话框! 上面这个程序只是演示用的,很简单。然后我就满怀希望地对公司的程序也做了类似的处理,然后悲剧发生了,竟然编译都通不过!编译错误是C2712:cannot use __try in functions that require object unwinding。于是又google了一番。msdn真的很棒,资料丰富,这下有时msdn上的方法解决的。详见http://msdn.microsoft.com/en-us/library/xwtb73ad%28VS.80%29.aspx With /EHsc, a function with structured exception handling cannot have objects that require unwinding (destruction). 我们的程序里出现了有析构函数的对象,同时编译参数又有/EHsc,于是出现编译错误了。可以参考下这篇文章http://se.csai.cn/ExpertEyes/No163.htm 作为一个例子,如果我们把上面的程序改成下面的就可能出现上述问题class Shit {
public:
Shit() {}
~Shit() {}
};
int main(int, char**)
{
Q_TRY_BEGIN
Shit s;
int *a = 0;
*a = 0;
Q_TRY_END
Q_EXCEPT
printf("Exiting 0...\n");
fflush(NULL);
return 0;
} msdn提出3种方案,允许我复制下 Move code that requires SEH to another function. Rewrite functions that use SEH to avoid the use of local variables and parameters that have destructors. Do not use SEH in constructors or destructors. Compile without /EHsc. 显然前两种办法对代码改动太大了,不可取,那么就去掉/EHsc吧。由于我是用Qt写程序,有些编译选项都是默认设好的,我在pro文件里尝试定义QMAKE_CXXFLAGS竟然无效,不是很清楚为什么。一般是在qmake.config和prf文件里里可以找到。qmake.conf里找到相关的两行 QMAKE_CXXFLAGS_STL_ON = -EHsc
QMAKE_CXXFLAGS_EXCEPTIONS_ON = -EHsc 在我们工程文件里直接设这两个为空竟然可以。后来又看了下Makefile,发现生成Makefile会依赖exceptions.prf, stl.prf,而这两个会加入上面两个变量,比如stl.prf:CONFIG -= stl_off
QMAKE_CFLAGS *= $QMAKE_CFLAGS_STL_ON
QMAKE_CXXFLAGS *= $QMAKE_CXXFLAGS_STL_ON 于是在工程文件中加入CONFIG -= exceptions stl 或者CONFIG += exceptions_off stl_off 就解决问题了,而且比之前的方法优雅。看看Makefile里相关代码变成了$(QMAKE) -spec ..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\default CONFIG+=release -o Makefile pvplayer.pro
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\qconfig.pri:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\modules\qt_webkit_version.pri:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\qt_functions.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\qt_config.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\exclusive_builds.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\default_pre.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\win32\default_pre.prf:
..\config.pri:
..\pvcommon\pvcommon.pri:
..\config.pri:
..\log4qt\log4qt.pri:
..\config.pri:
..\qextserialport\qextserialport.pri:
..\config.pri:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\release.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\debug_and_release.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\default_post.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\win32\default_post.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\win32\rtti.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\shared.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\win32\embed_manifest_exe.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\win32\embed_manifest_dll.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\warn_on.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\qt.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\win32\thread.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\moc.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\win32\windows.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\win32\stl_off.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\win32\exceptions_off.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\resources.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\uic.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\yacc.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\lex.prf:
..\..\..\..\QtSDK\Desktop\Qt\4.7.4\msvc2008\mkspecs\features\incredibuild_xge.prf:
e:\QtSDK\Desktop\Qt\4.7.4\msvc2008\lib\qtmain.prl: 好,至此已经把弹出对话框的问题解决了。不过还值得深入研究,目前只是做到了会用的程度。还有就是linux下或其他平台上有无类似处理还没调查。应该也有,因为最近linux下的thunderbird一启动就崩溃,弹出对话框。有空继续研究。参考文献:http://msdn.microsoft.com/en-us/library/s58ftw19%28v=vs.80%29.aspxhttp://msdn.microsoft.com/en-us/library/xwtb73ad%28VS.80%29.aspxUse /EHa if you want to catch an exception raised with something other than a throw.http://msdn.microsoft.com/en-us/library/1deeycx5%28VS.80%29.aspxhttp://blog.csdn.net/bichenggui/article/details/4536534http://se.csai.cn/ExpertEyes/No163.htm
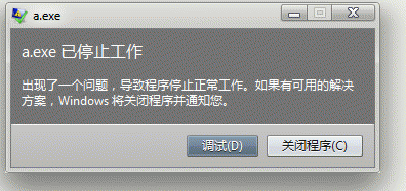
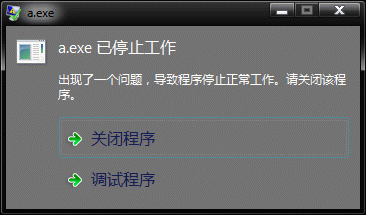
2
0 3114天前
7470
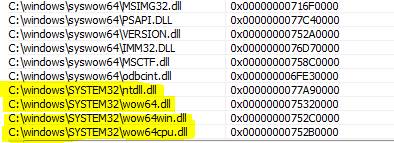
原文转自:https://bbs.pediy.com/thread-221236.htm 作者:mrMORE Windows操作系统作为PC上最普及的操作系统,面向的用户各种各样,因此在版本升级时,对比其它操作系统,兼容性都要做得好,不需要用户费神DIY处理一些BUG。64位windows上市后大多以前32位的程序依旧正常地运行,当然这里主要指用户态程序。那64位windows是如何支持32位程序运行的呢?之前在看《windows核心编程》一书时只知道这个机制的名字叫wow64,但是具体如何实现的一无所知。为此我上网查阅资料,结果相关文章都讲得很笼统,包括Microsoft官方文档也是从很上层架构上进行了介绍,对于搞逆向的人来说,只了解架构不看代码怎么能忍,windows就在手边,何不亲自研究窥探一把庐山面目呢?说搞就搞,从代码的角度看一下这个wow64的大概。这里插一句,其实在着手了解wow64机制前,是另外一个问题先引起了我的好奇:64位CPU比32位CPU除了每个寄存器宽度多了32bit,还多了几个通用寄存器:R8, R9, R10, R11, R12, R13, R14, R15,那32位程序在win64上运行时这些新加的寄存器就没用了吗?这个问题最后也会得到解决。首先,先从宏观分析一下,32位程序的运行需要软硬件两个大方面的支持:1)硬件上,CPU的解码模式需要是32位模式。64位CPU(我只熟悉INTEL的)是通过GDT表中CS段所对应的表项中L标志位来确定当前解码模式的。这里不展开描述GDT表与CPU运行模式的关系,感兴趣的可以参看 http://www.secbox.cn/hacker/program/9875.html2)软件上,操作系统需要提供32位的用户态运行时环境(C库,WINDOWS API)对32位程序支持,其次因为win64内核是64位模式的,所以32位运行时环境在与64位内核交互时需要有状态转换。当然另外肯定还有大量其它的兼容32位软件所需要实现的功能,比如资源管理,句柄管理,结构化错误管理等等,这些属于细节就不进行研究了,我这里先看一个大体。好了,接下来针对上面的分析进行探索。关于32位运行时环境这点,可以在c:/windows/syswow64中发现许多和c:/windows/system32下同名的动态链接库,如kernel32.dll, ntdll.dll, msvcrt.dll, ws2_32.dll等,其实这些都是32位的版本。像wow64名字所传达的含义一样,syswow64文件夹下的这些库相当于在64位windows中构建了一个32位windows子系统环境,我们32位的程序能正常在win64上运行正是靠这个子环境负责与64位环境进行了交互和兼容,所以需要重点探究下这个32位子环境是如何与win64环境交互的。我这里用到的工具是 PCHunter 与调试器 MDebug,静态分析工具 IDA。了解 windows 的读者都知道 ntdll.dll 是用户态与内核态交互的桥梁,所以我选择从 ntdll.dll 入手,选择了逻辑简单的 NtAllocateVirtualMemory 函数。首先看一下原生32位操作系统里这个函数是什么样的。我手头有个 win8 32bit 版本,利用 MDebug 直接转到 NtAllocateVirtualMemory 函数查看反汇编,可以看到,在设置好调用号 0x19B 之后直接就使用 sysenter 进行了系统调用,中间没有其它操作,下面是相应的反汇编代码:NtAllocateVirtualMemory:
7778F048 mov eax, 0x19B
7778F04D call sub_7778F055(7778F055)
7778F052 ret 0x18
sub_7778F055:
7778F055 mov edx, esp
7778F057 sysenter
7778F059 ret看完原生32位操作系统里的样子,win64 中运行一个 32 位程序时它的进程空间里的NtAllocateVirtualMemory 是一番什么情景呢?我手头有 win7 64bit 版,运行的一个32bit程序进行调试,可以看到 NtAllocateVirtualMemory 的形式如下:NtAllocateVirtualMemory:
77C8FAD0 mov eax,0x15
77C8FAD5 xor ecx,ecx
77C8FAD7 lea edx,[esp+0x4]
77C8FADB call dword ptr fs:[000000C0]
77C8FAE2 add esp,4
77C8FAE5 ret 0x18OK,区别很明显,wow64中的 ntdll.dll 与原生32位 windows 中的 ntdll.dll 有了变动,它不再是与内核交互的最后一个用户态模块,而是call 进了fs:[C0]处的函数,隐约感觉这里就是打开wow64秘密的入口。fs:[C0] 是什么呢?Windows操作系统中,fs寄存器用于记录线程环境块TEB,根据TEB结构体定义可以看出0xC0偏移处的定义为:PVOID WOW32Reserved; // 0C0其实在wow64之前还有wow32机制,用于兼容16位程序在32位windows上运行,与wow64异曲同工。所以 windows 系统在 wow64 中直接也拿这个保留位置用于进行32位64位环境切换的跳板。单步跟进,发现fs:[C0]处只有一行代码:752B2320 jmp 0033:752B271E这里是一个长跳转,目的地址是内存752B271E处,但是MDebug调试器显示752B271E处于未知模块。这时需要借助PCHunter,通过PcHunter发现该地址其实位于一个叫wow64cpu.dll的模块中,值得注意的一点是,该模块来自 system32 而非syswow64 目录,是64位的文件模块,也就是说,wow64下32位程序的进程空间内同时加载了32位与64位的可执行文件模块!在这个32位程序的进程空间里一共有4个来自SYSTEM32 目录64位的“客人”:终于,这里有了真正的64位 ntdll.dll 的出现。所以很容易可以推断,wow64.dll, wow64win.dll, wow64cpu.dll 组成了环境转换模块,而最终依然是ntdll.dll 负责与内核交互,wow64中这4个模块在默默地在后台支持着32位程序的运行。上面说到这里经历了一个长跳转,段寄存器由0x23变换为0x33,在win64中,0x23和0x33所对应的GDT表项中CPU的模式分别为32位与64位。自此,CPU解码模式由32位切换为64位。当然,故事还没结束。不过由于调试器是32位,无法准确捕获接下来发生的事情,单步跟进也没用了,我们转为使用IDA静态分析。找到 752B271E 所对应的 wow64cpu.dll 中的位置:00000000752B271E mov r8d,[esp] //取出返回地址
00000000752B2723 mov [r13+0xBC],r8d //保存返回地址
00000000752B272A mov [r13+0xC8],esp //保存32位环境堆栈指针
00000000752B2731 mov rsp,[r12+0x1480] //切换至64位环境堆栈
00000000752B2739 and qword ptr [r12+0x1480],0x0
00000000752B2742 mov r11d,edx
00000000752B2745 jmp qword ptr [r15+rcx*8]第一句读取[esp]的值其实是把返回地址取出,接着保存到了r13所指向的地方,同时还保存了esp,然后重新赋值了rsp。看了这一小段,我们基本可以猜测到,在wow64中那个幕后的64位环境里其实是有自己的堆栈和执行上下文的,在CPU由32位切换到64位后,堆栈也相应切换。好了,下面要搞最后一句跳向了哪里,也就是[r15+rcx*8]的值,我们上面考察的 NtAllocateVirtualMemory 有 xor ecx, ecx 的操作,所以到这里时rcx = 0,所以就我们考察的例子而言,最后就是跳转到了[r15]。那,r15的值是多少?这是有点棘手的问题。Wow64中32位程序只能由32位调试器调试,但是32位调试器下又无法获得64位模式下才可见的r15的值,怎么办?我这里使用shellcode的方式,利用32位MDebug调试shellcode的功能调试精心准备的一段shellcode,这段shellcode的作用独特而简单:让CPU切换到64位模式下“潇洒走一回”,将R8 ~R15的值记录到堆栈中,接着切换回32位模式。shellcode的二进制为:\x6A\x33\xE8\x00\x00\x00\x00\x83\x04\x24\x05\xCB\x48\xB8\x88\x77\x66\x55\x44\x33\x22\x11\x50\x41\x50\x41\x51\x41\x52\x41\x53\x41\x54\x41\x55\x41\x56\x41\x57\x50\xE8\x00\x00\x00\x00\xC7\x44\x24\x04\x23\x00\x00\x00\x83\x04\x24\x0D\xCB它的反汇编如下:/*开始时CPU处于32位模式*/
Push 0x33 // cs = 0x33
Call L1
L1:
add [esp], 5
retf // far ret,切换CPU状态
/*此时CPU处于64位模式*/
mov rax, 1122334455667788h //将r8~r15用特殊值与周边数据隔开,方便查看
push rax
push r8
push r9
push r10
push r11
push r12
push r13
push r14
push r15
push rax
Call L2:
L2:
mov [esp + 4], 0x23 // cs = 0x23
add [esp], 0xd
retf虽然32位调试器无法对64位代码运行时下断,但是可以在切换回32位模式后的地方下断点。所以在这段代码后下一个断,运行代码。执行完毕后,查看一下堆栈上的收获: 地址 内容
0018FEA0 1122334455667788
0018FEA8 00000000752B2450 r15
0018FEB0 000000000008EC80 r14
0018FEB8 000000000008FD20 r13
0018FEC0 000000007EFDB000 r12
0018FEC8 0000000000000246 r11
0018FED0 0000000000000000 r10
0018FED8 0000000077C8FAFA r9
0018FEE0 000000000000002B r8
0018FEE8 1122334455667788 Bingo!我们成功获得到了32位程序运行环境下R8~R15的值,根据R15的值定位出它同样位于wow64cpu.dll文件模块内,根据R15的值 找到wow64cpu.dll中相应的位置,发现是指向了一堆函数指针:.text:0000000078B62450 dq offset TurboDispatchJumpAddressEnd
.text:0000000078B62458 dq offset sub_78B62DBA
.text:0000000078B62460 dq offset sub_78B62BCE
.text:0000000078B62468 dq offset sub_78B62D6A
//后面还有很多函数指针,此处省略其实在第一次打开wow64cpu.dll寻找752B271E位置时,就可以看到它附近有一个名为CpuSimulate的函数,里面有这样的操作:.text:0000000078B625F9 mov r12, gs:30h
.text:0000000078B62602 lea r15, off_78B62450可以看到r15是指向了偏移78B62450处,对应动态加载后就是752B2450。所以这也印证了我们的实验结果。另外还可以看到的一点是r12指向了64位下的TEB(64位下gs段寄存器用于记录TEB结构)。所以很显然,[r15]是指向了TurboDispatchJumpAddressEnd处,就是上文jmp qword ptr [r15+rcx*8]所要跳转到的地方(因为ecx = 0),看一下它的代码:TurboDispatchJumpAddressEnd:
.text:0000000078B62749 mov [r13+0A4h], esi
.text:0000000078B62750 mov [r13+0A0h], edi
.text:0000000078B62757 mov [r13+0A8h], ebx
.text:0000000078B6275E mov [r13+0B8h], ebp //保存32位环境下的寄存器
.text:0000000078B62765 pushfq
.text:0000000078B62766 pop rbx
.text:0000000078B62767 mov [r13+0C4h], ebx //保存32位环境的eflags
.text:0000000078B6276E mov ecx, eax //调用号
.text:0000000078B62770 call cs:Wow64SystemServiceEx //继续完成未尽竟的事业
.text:0000000078B62776 mov [r13+0B4h], eax
.text:0000000078B6277D jmp loc_78B62611上面的代码最后跳转到78B62611,loc_78B62611的代码如下:text:0000000078B62611 loc_78B62611:
.text:0000000078B62611 and dword ptr [r13+2D0h], 1
.text:0000000078B62619 jz loc_78B626CE
.text:0000000078B6261F movaps xmm0, xmmword ptr [r13+170h]
.text:0000000078B62627 movaps xmm1, xmmword ptr [r13+180h]
.text:0000000078B6262F movaps xmm2, xmmword ptr [r13+190h]
.text:0000000078B62637 movaps xmm3, xmmword ptr [r13+1A0h]
.text:0000000078B6263F movaps xmm4, xmmword ptr [r13+1B0h]
.text:0000000078B62647 movaps xmm5, xmmword ptr [r13+1C0h]
.text:0000000078B6264F mov ecx, [r13+0B0h]
.text:0000000078B62656 mov edx, [r13+0ACh]
.text:0000000078B6265D and dword ptr [r13+2D0h], 0FFFFFFFEh
.text:0000000078B62665 mov edi, [r13+0A0h]
.text:0000000078B6266C mov esi, [r13+0A4h]
.text:0000000078B62673 mov ebx, [r13+0A8h]
.text:0000000078B6267A mov ebp, [r13+0B8h]
.text:0000000078B62681 mov eax, [r13+0B4h] //恢复32位环境寄存器
.text:0000000078B62688 mov [r12+1480h], rsp //保存64位环境堆栈指针
.text:0000000078B62690 mov [rsp+0B8h+var_B0], 23h
.text:0000000078B62697 mov [rsp+0B8h+var_98], 2Bh
.text:0000000078B6269E mov r8d, [r13+0C4h] //之前保存的32位环境eflags
.text:0000000078B626A5 and dword ptr [r13+0C4h], 0FFFFFEFFh
.text:0000000078B626B0 mov [rsp+0B8h+var_A8], r8d
.text:0000000078B626B5 mov r8d, [r13+0C8h]
.text:0000000078B626BC mov [rsp+0B8h+var_A0], r8
.text:0000000078B626C1 mov r8d, [r13+0BCh]
.text:0000000078B626C8 mov [rsp+0B8h+var_B8], r8
.text:0000000078B626CC iretq //排好堆栈,返回至32位模式返回地址处可以看到,在 TurboDispatchJumpAddressEnd 代码片段中,调用了一个外部函Wow64SystemServiceEx,由这个函数再继续把下面的事情做完,最终调用64位的 ntdll.dll的 NtAllocateVirtualMemory 来完成整个操作。TurboDispatchJumpAddressEnd 最后跳转至78B62611,将CPU主要寄存器值恢复至之前保存好的32位环境中的值,同时在堆栈中排布好返回地址,cs段寄存器值,eflag值,执行iretq,返回至32位环境中,在我们的例子中,即返回到 NtAllocateVirtualMemory 中 call dword ptr fs:[C0] 的下一句,看起来像真的执行了一个普通函数一样。上面讲到跳转的函数指针表是根据r15+rcx*8来得到的,在32位进程空间的那个ntdll.dll里面 call dword ptr fs:[C0] 前都有对ecx的赋值,我们可以推测在wow64中,系统调用被分成多类,类别号存在于rcx中,根据rcx的值来进行不同类别的模拟转换。Wow64SystemServiceEx 做的事情就暂时不详细研究了,感兴趣的可以细细钻研。对这次简单的wow64之旅做个小总结:1) windows/syswow64目录下的大量DLL库与SYSTEM32目录下的wow64.dll, wow64cpu.dll, wow64win.dll, ntdll.dll 支撑着wow64机制。2) Wow64下32位进程中实际有32位和64位两个逻辑子空间,每个子空间都 有各自的数据结构、堆栈,64位子空间负责与操作系统内核交互:32位用户态模式 <---------> 64位用户态模式 <------------------> 64位内核3)Wow64模式下,那些不可见的寄存器并不都是闲置不用的,在切换到64位环境后全部启用,和正常64位程序无差别。且经过分析可以知道有确切作用的寄存器有:R12: 指向64位环境的TEB结构体 R13:指向保存32位环境CPU的状态的位置R15: 指向跳转函数指针列表的起始上面是针对win7下做的一个wow64机制小探索,我也简单看了下在win8和win10下的wow64过程,在反汇编代码上有些小不同,但是逻辑原理是完全相同的,感兴趣的读者可以搞一把。
5
0 3219天前
7065
原文转载自:https://www.zhihu.com/question/27971703 作者:pezy根据 Appending Binary Files Using the COPY Command 可粗略的认为,就是以二进制的方式合并两个文件到一个新文件中。举例说明:echo Hello > 1.txt
echo World > 2.txt
copy /b 1.txt+2.txt 3.txt
那么此刻 3.txt 中应该是Hello
World
如果仅仅实现上述例子中的基本功能,使用几个系统的 API 就可以搞定。代码如下:#include <windows.h>
#include <stdio.h>
void main()
{
HANDLE hFile;
HANDLE hAppend;
DWORD dwBytesRead, dwBytesWritten, dwPos;
BYTE buff[4096];
// Copy the existing file.
BOOL bCopy = CopyFile(TEXT("1.txt"), TEXT("3.txt"), TRUE);
if (!bCopy)
{
printf("Could not copy 1.txt to 3.txt.");
return;
}
// Open the existing file.
hFile = CreateFile(TEXT("2.txt"), // open 2.txt
GENERIC_READ, // open for reading
0, // do not share
NULL, // no security
OPEN_EXISTING, // existing file only
FILE_ATTRIBUTE_NORMAL, // normal file
NULL); // no attr. template
if (hFile == INVALID_HANDLE_VALUE)
{
printf("Could not open 2.txt.");
return;
}
// Open the existing file, or if the file does not exist,
// create a new file.
hAppend = CreateFile(TEXT("3.txt"), // open 3.txt
FILE_APPEND_DATA, // open for writing
FILE_SHARE_READ, // allow multiple readers
NULL, // no security
OPEN_ALWAYS, // open or create
FILE_ATTRIBUTE_NORMAL, // normal file
NULL); // no attr. template
if (hAppend == INVALID_HANDLE_VALUE)
{
printf("Could not open 3.txt.");
return;
}
// Append the first file to the end of the second file.
// Lock the second file to prevent another process from
// accessing it while writing to it. Unlock the
// file when writing is complete.
while (ReadFile(hFile, buff, sizeof(buff), &dwBytesRead, NULL)
&& dwBytesRead > 0)
{
dwPos = SetFilePointer(hAppend, 0, NULL, FILE_END);
LockFile(hAppend, dwPos, 0, dwBytesRead, 0);
WriteFile(hAppend, buff, dwBytesRead, &dwBytesWritten, NULL);
UnlockFile(hAppend, dwPos, 0, dwBytesRead, 0);
}
// Close both files.
CloseHandle(hFile);
CloseHandle(hAppend);
}
将代码中的 1.txt, 2.txt, 3.txt 改为任何别的文件,是一样的。如题主补充的要求,做如下替换即可:1.txt -> a.jpg2.txt -> b.txt3.txt -> c.txt (文本),c.jpg(更改后缀,成为图片)诸如 jpg 之类的格式,依然是二进制文件,经过渲染,表现为图片而已。
5
0 3258天前
7367
本篇内容,用编程思想自制空调,包括完整的软件开发阶段,同时针对此设计进行总结与优化。开发背景——停电了,不能编程,空调也不能用。这……不能编程可以,不吹空调简直不能忍啊,怎么处理?需求分析——使用现有的工具,以及技术完成小型空调的设计,要能够制冷。框架:使用某宝的小风扇(JDK源代码),以及制冷核心物品:冰块(JDK工厂函数)。开发工具:螺丝刀套件(eclipse),生产冰块的工具(工厂模式)开发平台:桌子(Java)多线程:在设计小空调的同时,首先使用别的开发工具(冰箱)冻冰块。疑问:空调还需要冰块,冰块还得去冰箱冻,不是更浪费资源么?并非如此,即使冻冰块使用电量,小空调运作需要电量,但是加起来也远不止真正的空调运行需要的电量。所以,此物十足就是小型空调啊,只是内部机理不同。软件设计和编码1.首先准备材料,风扇,载体,剪刀,胶带,螺丝刀……2.首先要继承“小风扇”这个类,只需要找出其中的方法进行重写,方法使用。3.将空调外壳(显示层)和内核层之间做做个接口。4.接口做好了,但是最简单的接口,必须进行修改才能使用。5.修改接口,加固衔接部分。6.使用重写的方法进行交互,使用方法实现类中成员属性螺丝拧上去。7.核心电机做好了,进行显示层包装,对显示层进行修改,让冷风能够按要求吹出去。8.进行简单的修改以后发现前端松松垮垮,不会按照我们的需求输出内容,所以给输出口加个CSS样式。软件测试加好CSS样式以后,放入冰块进行测试:结果发现:电机漏风严重!马上追加补丁修复漏洞。nice!完成总结于展望总结:使用工具类进行程序设计,基本功能已经完成。虽然还是多余的使用冰块,但是最终用的电量还是比空调少,自然能力也比空调弱,就是小的空调。展望:风力不够,需要修改硬件。系统的耦合度太高,不便于维护,今后的开发一定要控制好耦合度!!
5
0 3265天前
6852
转载自:http://www.cnblogs.com/leadzen/archive/2008/09/06/1285764.html你知道世界上有多少种浏览器吗?除了我们熟知的IE, Firefox, Opera, Safari四大浏览器之外,世界上还有近百种浏览器。 几天前,浏览器家族有刚诞生了一位小王子,就是Google推出的Chrome浏览器。由于Chrome出生名门,尽管他还是个小家伙,没有人敢小看他。以后,咱们常说浏览器的“四大才子”就得改称为“五朵金花”了。 在网站前端开发中,浏览器兼容性问题本已让我们手忙脚乱,Chrome的出世不知道又要给我们添多少乱子。浏览器兼容性是前端开发框架要解决的第一个问题,要解决兼容性问题就得首先准确判断出浏览器的类型及其版本。 JavaScript是前端开发的主要语言,我们可以通过编写JavaScript程序来判断浏览器的类型及版本。JavaScript判断浏览器类型一般有两种办法,一种是根据各种浏览器独有的属性来分辨,另一种是通过分析浏览器的userAgent属性来判断的。在许多情况下,值判断出浏览器类型之后,还需判断浏览器版本才能处理兼容性问题,而判断浏览器的版本一般只能通过分析浏览器的userAgent才能知道。 我们先来分析一下各种浏览器的特征及其userAgent。 IE 只有IE支持创建ActiveX控件,因此她有一个其他浏览器没有的东西,就是ActiveXObject函数。只要判断window对象存在ActiveXObject函数,就可以明确判断出当前浏览器是IE。而IE各个版本典型的userAgent如下: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0) Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2) Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1) Mozilla/4.0 (compatible; MSIE 5.0; Windows NT) 其中,版本号是MSIE之后的数字。 Firefox Firefox中的DOM元素都有一个getBoxObjectFor函数,用来获取该DOM元素的位置和大小(IE对应的中是getBoundingClientRect函数)。这是Firefox独有的,判断它即可知道是当前浏览器是Firefox。Firefox几个版本的userAgent大致如下: Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1 Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3 Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12 其中,版本号是Firefox之后的数字。 Opera Opera提供了专门的浏览器标志,就是window.opera属性。Opera典型的userAgent如下: Opera/9.27 (Windows NT 5.2; U; zh-cn) Opera/8.0 (Macintosh; PPC Mac OS X; U; en) Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0 其中,版本号是靠近Opera的数字。 Safari Safari浏览器中有一个其他浏览器没有的openDatabase函数,可做为判断Safari的标志。Safari典型的userAgent如下: Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (KHTML, like Gecko) Version/3.1 Safari/525.13 Mozilla/5.0 (iPhone; U; CPU like Mac OS X) AppleWebKit/420.1 (KHTML, like Gecko) Version/3.0 Mobile/4A93 Safari/419.3 其版本号是Version之后的数字。 Chrome Chrome有一个MessageEvent函数,但Firefox也有。不过,好在Chrome并没有Firefox的getBoxObjectFor函数,根据这个条件还是可以准确判断出Chrome浏览器的。目前,Chrome的userAgent是: Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13 其中,版本号在Chrome只后的数字。 有趣的是,Chrome的userAgent还包含了Safari的特征,也许这就是Chrome可以运行所有Apple浏览器应用的基础吧。 只要了解了以上信息,我们就可以根基这些特征来判断浏览器类型及其版本了。我们会将判断的结果保存在Sys名字空间中,成为前端框架的基本标志信息,供今后的程序来读取。如果判断出谋种浏览器,Sys名字空间将有一个该浏览器名称的属性,其值为该浏览器的版本号。例如,如果判断出IE 7.0,则Sys.ie的值为7.0;如果判断出Firefox 3.0,则Sys.firefox的值为3.0。下面是判断浏览器的代码:<script type="text/javascript">
var Sys = {};
var ua = navigator.userAgent.toLowerCase();
if (window.ActiveXObject)
Sys.ie = ua.match(/msie ([\d.]+)/)[1]
else if (document.getBoxObjectFor)
Sys.firefox = ua.match(/firefox\/([\d.]+)/)[1]
else if (window.MessageEvent && !document.getBoxObjectFor)
Sys.chrome = ua.match(/chrome\/([\d.]+)/)[1]
else if (window.opera)
Sys.opera = ua.match(/opera.([\d.]+)/)[1]
else if (window.openDatabase)
Sys.safari = ua.match(/version\/([\d.]+)/)[1];
//以下进行测试
if(Sys.ie) document.write('IE: '+Sys.ie);
if(Sys.firefox) document.write('Firefox: '+Sys.firefox);
if(Sys.chrome) document.write('Chrome: '+Sys.chrome);
if(Sys.opera) document.write('Opera: '+Sys.opera);
if(Sys.safari) document.write('Safari: '+Sys.safari);
</script> 我们把对IE的判断放在第一,因为IE的用户最多,其次是判断Firefox。按使用者多少的顺序来判断浏览器类型,可以提高判断效率,少做无用功。之所以将Chrome放在第三判断,是因为我们预测Chrome很快会成为市场占有率第三的浏览器。其中,在分析浏览器版本时,用到了正则表达式来析取其中的版本信息。 如果你的JavaScript玩得很高,你还可以将前面的判断代码写成这样:<script type="text/javascript">
var Sys = {};
var ua = navigator.userAgent.toLowerCase();
window.ActiveXObject ? Sys.ie = ua.match(/msie ([\d.]+)/)[1] :
document.getBoxObjectFor ? Sys.firefox = ua.match(/firefox\/([\d.]+)/)[1] :
window.MessageEvent && !document.getBoxObjectFor ? Sys.chrome = ua.match(/chrome\/([\d.]+)/)[1] :
window.opera ? Sys.opera = ua.match(/opera.([\d.]+)/)[1] :
window.openDatabase ? Sys.safari = ua.match(/version\/([\d.]+)/)[1] : 0;
//以下进行测试
if(Sys.ie) document.write('IE: '+Sys.ie);
if(Sys.firefox) document.write('Firefox: '+Sys.firefox);
if(Sys.chrome) document.write('Chrome: '+Sys.chrome);
if(Sys.opera) document.write('Opera: '+Sys.opera);
if(Sys.safari) document.write('Safari: '+Sys.safari);
</script> 这样可以使JavaScript代码更精简些。当然,可读性稍差一些,就看你是重视效率还是重视可维护性了。 使用不同特征来判断浏览器的方法,虽然在速度上比用正则表达式分析userAgent要来的快,不过这些特征可能会随浏览器版本而变化。比如,一种浏览器本来独有的特性取得了市场上的成功,其他浏览器也就可能跟着加入该特性,从而使该浏览器的独有特征消失,导致我们的判断失败。因此,相对比较保险的做法是通过解析userAgent中的特征来判断浏览器类型。何况,反正判断版本信息也需要解析浏览器的userAgent的。 通过分析各类浏览器的userAgent信息,不难得出分辨各类浏览器及其版本的正则表达式。而且,对浏览器类型的判断和版本的判断完全可以合为一体地进行。于是,我们可以写出下面的代码:<script type="text/javascript">
var Sys = {};
var ua = navigator.userAgent.toLowerCase();
var s;
(s = ua.match(/msie ([\d.]+)/)) ? Sys.ie = s[1] :
(s = ua.match(/firefox\/([\d.]+)/)) ? Sys.firefox = s[1] :
(s = ua.match(/chrome\/([\d.]+)/)) ? Sys.chrome = s[1] :
(s = ua.match(/opera.([\d.]+)/)) ? Sys.opera = s[1] :
(s = ua.match(/version\/([\d.]+).*safari/)) ? Sys.safari = s[1] : 0;
//以下进行测试
if (Sys.ie) document.write('IE: ' + Sys.ie);
if (Sys.firefox) document.write('Firefox: ' + Sys.firefox);
if (Sys.chrome) document.write('Chrome: ' + Sys.chrome);
if (Sys.opera) document.write('Opera: ' + Sys.opera);
if (Sys.safari) document.write('Safari: ' + Sys.safari);
</script> 其中,采用了“... ? ... : ...”这样的判断表达式来精简代码。判断条件是一条赋值语句,既完成正则表达式的匹配及结果复制,又直接作为条件判断。而随后的版本信息只需从前面的匹配结果中提取即可,这是非常高效的代码。 以上的代码都是为了打造前端框架所做的预研,并在五大浏览器上测试通过。今后,判断某种浏览器只需用if(Sys.ie)或if(Sys.firefox)等形式,而判断浏览器版本只需用if(Sys.ie == '8.0')或if(Sys.firefox == '3.0')等形式,表达起来还是非常优雅的。 前端框架项目已经启动,一切就看过程和结果了...IE11(转载自:http://keenwon.com/851.html) : $(function () {
var Sys = {};
var ua = navigator.userAgent.toLowerCase();
var s;
(s = ua.match(/rv:([\d.]+)\) like gecko/)) ? Sys.ie = s[1] :
(s = ua.match(/msie ([\d.]+)/)) ? Sys.ie = s[1] :
(s = ua.match(/firefox\/([\d.]+)/)) ? Sys.firefox = s[1] :
(s = ua.match(/chrome\/([\d.]+)/)) ? Sys.chrome = s[1] :
(s = ua.match(/opera.([\d.]+)/)) ? Sys.opera = s[1] :
(s = ua.match(/version\/([\d.]+).*safari/)) ? Sys.safari = s[1] : 0;
if (Sys.ie) $('span').text('IE: ' + Sys.ie);
if (Sys.firefox) $('span').text('Firefox: ' + Sys.firefox);
if (Sys.chrome) $('span').text('Chrome: ' + Sys.chrome);
if (Sys.opera) $('span').text('Opera: ' + Sys.opera);
if (Sys.safari) $('span').text('Safari: ' + Sys.safari);
});
在线演示:http://keenwon.com/demo/201402/js-check-browser.html
6
0 3281天前
7879
UTF-8 页面在IE显示中文乱码解决方案 将 <meta. http-equiv="Content-Type" content="text/html; charset=UTF-8" /> 写在title前面。起因 这个问题要从浏览器解析html的方式讲起。浏览器读取了页面的html代码后开始进行解析。解析前浏览器要先知道页面的编码方式,然后根据编码方式进行解码,然后才能开始解析。我大概想了一下,浏览器可以从下面3个方面得到页面编码方式:HTTP Header中的"Content-Type"项、返回的html代码开头是否有BOM、html代码中的meta标签。 浏览器(无论是IE还是Firefox)在解析页面时,首先取HTTP Header中的Content-Type项,如果有写明charset的话就认定页面的编码方式为charset指定的值。如果没有指明,则认定为默认值。根据上表,IE中文版的默认值是GB2312,Firefox中文版的默认值是GBK,不过IE的GB2312好像和GBK没啥区别。然后,浏览器会看一下有没有BOM。一旦发现有UTF-8的3字节BOM,则重新认定页面的编码方式为UTF-8。 然后是解码阶段,解码完成后是解析html的阶段。解析html的过程中,当解析到head部分的meta标签时,浏览器会根据<meta. http-equiv="Content-Type" content="text/html; charset=UTF-8" />这个语句中的说明,重新认定编码方式为charset后面的方式,中断html解析过程,返回到解码步骤重新解码。 知道了这个步骤,再来看这个表:在加了Header语句设置了HTTP Header后,两个浏览器解析所有页面都是用的UTF-8方式,包括GBK编码的页面。(当然要正常解析GBK编码的文件,可以在title前加上个meta标签标明编码方式。)在上表的下半部分可以清楚的看到这一点。再来看上半部分,在没有加Header语句的页面里,首先浏览器认定页面编码方式为默认值GBK。 检测有无UTF-8的3字节BOM,检测到的,认定页面编码方式为UTF-8,解码再解析html,一切正常。如上表所示,上半部分带BOM的页面都能正常显示。如果没有BOM,页面可能是GBK或者UTF-8(no BOM)格式,浏览器会先按照默认的GBK方式开始解码。页面为GBK格式时,无meta时正常,有meta时浏览器解析到meta标签会回头重现按UTF-8方式解码,所以GBK,meta在前或后,无论IE还是FF都是乱码。再看UTF-8(no BOM)的页面,无meta时FF用GBK方式解码下去,最终显示乱码,IE则解码出错,形成空白页。有meta时,Firefox找到meta后回头重新按UTF-8方式解码,所以无论meta在前或在后都是正常;IE则是在meta在前时能够和Firefox一样回头重新解码,当meta在后时,又是解析到title出错,返回空白页。
6
0 3285天前
6177
一个较经典的PHP文件上传类代码,虽然很老,但用的人还是挺多的,当初自己在用PHP做站的时候,就用了这个类。包括有调用的例子,对新手也友好,这个类可以上传图片和其它格式的文件,看你怎么设置了。另外这个上传类可对文件上传大小限制,可自动创建文件上传目录,类中的方法用好了,可以扩展较多的功能。<?php
// $Id: upload.class.php,v 1.0 2001/10/14 14:06:57 whxbb Exp $
$UPLOAD_CLASS_ERROR = array( 1 => '不允许上传该格式文件',
2 => '目录不可写',
3 => '文件已存在',
4 => '不知名错误',
5 => '文件太大'
);
/**
* Purpose
* 文件上传
* Example
*
$fileArr['file'] = $file;
$fileArr['name'] = $file_name;
$fileArr['size'] = $file_size;
$fileArr['type'] = $file_type;
// 所允许上传的文件类型
$filetypes = array('gif','jpg','jpge','png');
// 文件上传目录
$savepath = "/usr/htdocs/upload/";
// 没有最大限制 0 无限制
$maxsize = 0;
// 覆盖 0 不允许 1 允许
$overwrite = 0;
$upload = new upload($fileArr, $file_name, $savepath, $filetypes, $overwrite, $maxsize);
if (!$upload->run())
{
echo $upload->errmsg();
}
*
* @author whxbb(whxbb@21cn.com)
* @version 0.1
*/
class upload
{
var $file;
var $file_name;
var $file_size;
var $file_type;
/** 保存名 */
var $savename;
/** 保存路径 */
var $savepath;
/** 文件格式限定 */
var $fileformat = array();
/** 覆盖模式 */
var $overwrite = 0;
/** 文件最大字节 */
var $maxsize = 0;
/** 文件扩展名 */
var $ext;
/** 错误代号 */
var $errno;
/**
* 构造函数
* @param $fileArr 文件信息数组 'file' 临时文件所在路径及文件名
'name' 上传文件名
'size' 上传文件大小
'type' 上传文件类型
* @param savename 文件保存名
* @param savepath 文件保存路径
* @param fileformat 文件格式限制数组
* @param overwriet 是否覆盖 1 允许覆盖 0 禁止覆盖
* @param maxsize 文件最大尺寸
*/
function upload($fileArr, $savename, $savepath, $fileformat, $overwrite = 0, $maxsize = 0) {
$this->file = $fileArr['file'];
$this->file_name = $fileArr['name'];
$this->file_size = $fileArr['size'];
$this->file_type = $fileArr['type'];
$this->get_ext();
$this->set_savepath($savepath);
$this->set_fileformat($fileformat);
$this->set_overwrite($overwrite);
$this->set_savename($savename);
$this->set_maxsize($maxsize);
}
/** 上传 */
function run()
{
/** 检查文件格式 */
if (!$this->validate_format())
{
$this->errno = 1;
return false;
}
/** 检查目录是否可写 */
if(!@is_writable($this->savepath))
{
$this->errno = 2;
return false;
}
/** 如果不允许覆盖,检查文件是否已经存在 */
if($this->overwrite == 0 && @file_exists($this->savepath.$this->savename))
{
$this->errno = 3;
return false;
}
/** 如果有大小限制,检查文件是否超过限制 */
if ($this->maxsize != 0 )
{
if ($this->file_size > $this->maxsize)
{
$this->errno = 5;
return false;
}
}
/** 文件上传 */
if(!@copy($this->file, $this->savepath.$this->savename))
{
$this->errno = 4;
return false;
}
/** 删除临时文件 */
$this->destory();
return true;
}
/**
* 文件格式检查
* @access protect
*/
function validate_format()
{
if (!is_array($this->fileformat)) // 没有格式限制
return true;
$ext = strtolower($this->ext);
reset($this->fileformat);
while(list($var, $key) = each($this->fileformat))
{
if (strtolower($key) == $ext)
return true;
}
reset($this->fileformat);
return false;
}
/**
* 获取文件扩展名
* access public
*/
function get_ext()
{
$ext = explode(".", $this->file_name);
$ext = $ext[count($ext) - 1];
$this->ext = $ext;
}
/**
* 设置上传文件的最大字节限制
* @param $maxsize 文件大小(bytes) 0:表示无限制
* @access public
*/
function set_maxsize($maxsize)
{
$this->maxsize = $maxsize;
}
/**
* 设置覆盖模式
* @param 覆盖模式 1:允许覆盖 0:禁止覆盖
* @access public
*/
function set_overwrite($overwrite)
{
$this->overwrite = $overwrite;
}
/**
* 设置允许上传的文件格式
* @param $fileformat 允许上传的文件扩展名数组
* @access public
*/
function set_fileformat($fileformat)
{
$this->fileformat = $fileformat;
}
/**
* 设置保存路径
* @param $savepath 文件保存路径:以 "/" 结尾
* @access public
*/
function set_savepath($savepath)
{
$this->savepath = $savepath;
}
/**
* 设置文件保存名
* @savename 保存名,如果为空,则系统自动生成一个随机的文件名
* @access public
*/
function set_savename($savename)
{
if ($savename == '') // 如果未设置文件名,则生成一个随机文件名
{
srand ((double) microtime() * 1000000);
$rnd = rand(100,999);
$name = date('Ymdhis') + $rnd;
$name = $name.".".$this->ext;
} else {
$name = $savename;
}
$this->savename = $name;
}
/**
* 删除文件
* @param $file 所要删除的文件名
* @access public
*/
function del($file)
{
if(!@unlink($file))
{
$this->errno = 3;
return false;
}
return true;
}
/**
* 删除临时文件
* @access proctect
*/
function destory()
{
$this->del($this->file);
}
/**
* 得到错误信息
* @access public
* @return error msg string or false
*/
function errmsg()
{
global $UPLOAD_CLASS_ERROR;
if ($this->errno == 0)
return false;
else
return $UPLOAD_CLASS_ERROR[$this->errno];
}
}
?>
5
0 3289天前
6638
首先我们需要找到php.ini所在的位置,这里我们可以通过php自带的phpinfo函数获取到上图中,可以看到我们的php.ini文件放在c:\php目录下,接下去,我们打开php.ini,首先找到file_uploads = on ;是否允许通过HTTP上传文件的开关。默认为ON即是开
upload_tmp_dir ;文件上传至服务器上存储临时文件的地方,如果没指定就会用系统默认的临时文件夹
upload_max_filesize = 8m ;望文生意,即允许上传文件大小的最大值。默认为2M
post_max_size = 8m ;指通过表单POST给PHP的所能接收的最大值,包括表单里的所有值。默认为8M一般地,设置好上述四个参数后,上传<=8M的文件是不成问题,在网络正常的情况下。但如果要上传>8M的大体积文件,只设置上述四项还一定能行的通。所以我们需要进一步配置以下的参数max_execution_time = 600 ;每个PHP页面运行的最大时间值(秒),默认30秒
max_input_time = 600 ;每个PHP页面接收数据所需的最大时间,默认60秒
memory_limit = 8m ;每个PHP页面所吃掉的最大内存,默认8M例如:max_execution_time = 600
max_input_time = 600
memory_limit = 32m
file_uploads = on
upload_tmp_dir = /tmp
upload_max_filesize = 32m
post_max_size = 32m把上述参数修改后,需要一定时间生效,如果不想等待可以直接结束PHP的进程或者重启PHP服务即可,好了,现在在网络所允许的正常情况下,就可以上传大体积文件了

5
0 3293天前
